 Liste de partage de Grorico
Liste de partage de Grorico
Les enjeux autour de la donnée sont en train de changer par rapport à ce que l’on connait depuis les SGBDR : volume de plus en plus important, nombre d’utilisateur croissant, accès concurrents et transactionnels intensifs à la fois en lecture et en écriture, haute disponibilité à des niveaux coûts acceptables, coût de licence. Dans un tel contexte, les bases de données traditionnelles peuvent montrer leurs limites.
Parmi les différentes réponses à ces enjeux que l’ont a vu émerger ces dernières années, deux d’entre elles se sont révélées particulièrement efficaces :
- L’utilisation d’architectures distribuées permet de répartir non seulement la charge mais aussi les données sur plusieurs fournisseurs de données. Les éditeurs de SGBD proposent d’ors et déjà des versions clusterisées de leurs solutions (Oracle RAC, MySQL Cluster, PGCluster, SQL Server cluster) et de nouvelles solutions « scalable-ready » apparaissent, portées par la mouvance NoSQL (Cassandra, HBase, MongoDB, CouchDB).
- L’utilisation de cache, pour chaque fournisseur de données, permet d’accélérer drastiquement les performances d’accès aux données. Certaines solutions appelées « memcache » ont été spécifiquement conçues pour proposer de tels systèmes. On peut citer par exemple Redis ou encore Memcached. Ces caches restent (encore bien souvent) limités à des architectures orientées « lecture ».
Les data grids ont challengé les SGBDR en réunissant les deux précédentes réponses : du partitionnement et du stockage mémoire (suivant les configurations choisies). Les acteurs sont multiples : Oracle, Gigaspaces mais également GemStone (VMWare)
1. GemFire, kesako ?
GemFire est la solution de cache distribué éditée par GemStone Systems, récemment acquis par VMWare. Encore appelé « VMware vFabric GemFire », GemFire est un composant de l’écosystème vFabric de VMware.
Cette solution propose, en plus de son framework, des mécanismes avancés de partitionnement (« sharding »), de persistance et de réplication. Ecrit en Java, GemFire peut fonctionner sur une JVM 32 ou 64 bits, c’est à dire sur n’importe quel OS compatible. Les clients peuvent être écrits à la fois en C++, C# ou Java grâce aux API fournies.
GemFire est un cache orienté-objet qui offre les services d’une base de donnée traditionnelle : OQL (une extension orientée objet du langage SQL), transactions (implémente l’interface JTA), cohérence des données (selon le paramétrage choisi), persistance sur disque (via les mécanismes de write behind ou write through), ou encore tolérance aux pannes.
En plus de ces fonctionnalités classiques, on retrouve également des mécanismes plus spécifiques comme le « continuous querying » permettant d’être notifié lorsque le résultat d’une requête a changé, ou le « function execution », permettant de distribuer un traitement au sein du clustrer GemFire. Ce sujet sera l’objet de la deuxième partie de cet article
1.1. Architecture de Gemfire
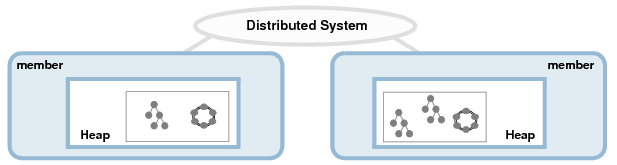
Un système distribué GemFire se compose de membres, des processus Java connectés les uns aux autres au travers d’un réseau. Chaque membre embarque un cache, fonctionnant soit en mode stockage (« data host ») soit en mode proxy (« data accessor »). Dans le premier cas, des données peuvent être écrite localement puis propagées ; dans l’autre cas, le cache agira comme une simple passerelle vers les données distantes contenues dans la grille de données.
On distingue ainsi deux types de membre :
- Le client, généralement une application embarquant un cache GemFire et connecté au système via une API.
- Le serveur (ou « cacheserver »), un membre spécialisé dans le stockage de données qui s’exécute de façon autonome dans une JVM dédiée.
Ces membres se découvrent entre eux de deux façons :
- Par l’intermédiaire de Locators. Ces sont des membres spécialisés qui maintiennent à jour une liste des membres composant l’architecture distribuée.
- Par multicast. Chaque nouveau membre manifeste sa présence en émettant sur une IP et un port préalablement défini.

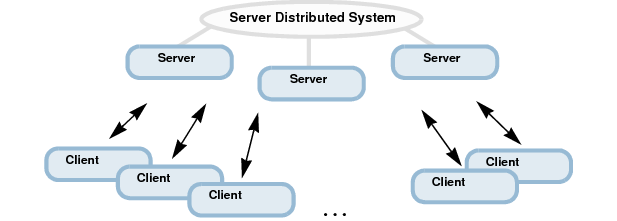
Dans le schéma précédent, on observe que le système distribué peut adopter plusieurs topologies :
- Peer-to-peer : les données sont partagées entre plusieurs clients (liens bleus).
- Client/serveur : les données sont partagées au sein d’un cluster dédié de serveurs sur lequel peuvent se connecter les clients (liens verts et gris).
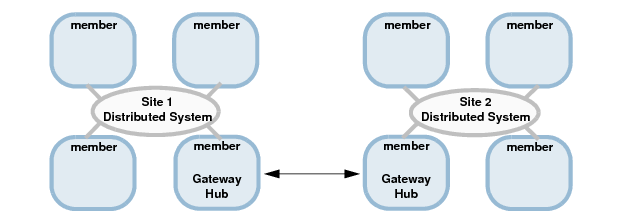
- Multi-site : plusieurs systèmes distribués sont reliés entre eux via un ou plusieurs membres déclarés en tant que « gateway hubs » (non représenté).
Pour synchroniser les différents nœuds, GemFire propose une API de propagation par delta permettant de réduire les échanges sur le réseau, surtout dans le cas de régions fortement répliquées.
1.2. La sémantique
Dans GemFire, le concept principal est celui de région. Une région, encore appelé « data set », est un groupe logique dans lequel sont stockées les données.
Chaque région possède sa propre configuration (modèle de données, type de partitionnement, présence de réplication, nature de la persistance, gestion des événements). Cette configuration devra être déclarée à l’identique dans chacun des membres utilisant la région. Elle se fait via un descripteur XML ou programmatiquement, au travers de l’API GemFire.
Toute région implémente la bien-connue interface java.util.Map : la manipuler ne devrait pas poser de problème ! Les données y sont donc stockées sous forme de clef/valeur. Clefs et valeurs prennent toutes deux la forme d’un objet Java, toutefois, la clef sera le plus souvent une simple chaine de caractères.
On dénombre 4 types de régions :
- Locale, la région n’est accessible que par le membre qui l’a déclaré et ne sera donc partagé avec aucun autre membre.
- Distribuée, chaque membre stock localement les données qu’il créé, mais les partages avec les autres membres du système.
- Répliquée, chacun des membres du système détient une copie complète de toutes les données de la région.
- Partitionnée, les données sont réparties au travers des différents membres de la région, soit équitablement, soit selon des règles de partitionnement préalablement définies. Il est de plus possible de répliquer ces données (« redundant copies ») sur un ou plusieurs membres, afin de garantir leur haute disponibilité. Ainsi chaque membre est responsable d’une partition et héberge n réplicas d’autres partitions.
GemFire offre 3 modes de distribution (ou « scope ») des données permettant d’assurer différents niveaux de cohérence :
- Distributed-no-ack : aucune contrainte n’est imposée lors de la propagation d’opérations. Ce niveau offre les meilleures performances, mais est sujet aux problèmes de concurrence.
- Distributed-ack : les opérations distribuées sont validées par un système d’acquittement. Ce niveau est moins exposé aux problèmes de concurrence
- Global : les entrées d’une région sont automatiquement verrouillées lorsqu’elles sont modifiées. C’est le seul scope permettant d’assurer une cohérence forte des données, mais c’est aussi le moins performant.
2. Distribuer un traitement
Le requêtage des données d’une région se fait via OQL. Ce langage répond à des besoins standard en autorisant l’utilisation de clauses SQL bien-connues telles que SELECT, FROM ou WHERE. Il est également possible de réaliser des jointures entre régions et des indexes.
Toutefois, les requêtes OQL sont soumises à certaines limitations qui dépendent principalement du type de région sur lequel on les exécute. Ces limitations concernent entre autre la cohérence des résultats dans le cas de régions répliquées ou distribuées. En effet, pour ces deux types de région, les requêtes sont effectuées sur les données contenues dans le cache local, qui peut, dans certains cas (race conditions, selon la stratégie de propagation), ne pas être cohérentes à un instant donné.
Lorsque l’on aborde la question du traitement au sein d’une architecture distribuée, on entend souvent parler de MapReduce. Le concept est simple : au lieu de rapatrier les données sur un nœud pour traitement, c’est la fonction réalisant ce traitement qui est envoyé sur chacun des nœuds, c’est à dire au plus proche de la donnée. Ceci offre l’avantage de paralléliser l’exécution de la fonction sur différents nœuds tout en diminuant les échanges au niveau du réseau.
Le « function execution service » fourni par GemFire, bien qu’assez éloigné de MapReduce, s’inspire de ce mécanisme. En voici les détails.
2.1. Mécanismes mis en jeu
Toute fonction distribuée doit être préalablement déclarée et déployée sur chaque membre d’une région partitionnée lors de son déploiement (descripteur + classpath). Cela implique que ces fonctions aient été préalablement codées en Java, compilées puis éventuellement packagées.
Lorsqu’un client déclenche l’exécution d’une fonction distribuée (action non bloquante pour le client), le serveur (data host) auquel il est connecté va notifier tous les autres serveurs du cluster, contenant localement une partie des données à traiter, d’engager l’exécution de ladite fonction.
Dans le cas ou la fonction retourne des résultats, les différents serveurs vont les soumettre à un collecteur de résultat contenu dans le serveur directement connecté au client. Ce collecteur accumule les résultats jusqu’à ce que chaque serveur ait notifié l’envoie du dernier résultat.
Le client peut alors les récupérer :
- de manière bloquante : attente de la totalité des résultats, possibilité de spécifier un timeout.
- de manière non bloquante : le résultat récupéré par le client est alors potentiellement incomplet.
La documentation ne spécifie aucun mécanisme de callback permettant de notifier de manière asynchrone la disponibilité d’un résultat complet.
Ces différentes étapes se résument dans le schéma suivant :

Remarque : le client peut restreindre l’exécution à un, une partie ou tous les membres d’une région. Il peut également spécifier directement les clefs qui seront soumise au traitement. Ces possibilités sont très utiles, par exemple lorsqu’a été défini une politique de partitionnement spécifique.
2.2. Contexte de l’exemple
Afin d’expérimenter le traitement distribué, nous nous sommes placé dans le contexte d’un service web. Cet exemple entre dans la continuité d’un POC réalisé en interne chez Octo. Nous avons souhaité calculer à la demande des informations statistiques sur la vitesse de véhicules au travers de données brutes remontées par ces derniers.
L’architecture visée se compose des éléments GemFire suivants :
- Deux CacheServer et un Locator, déployés sur une machine virtuelle
- Une application web JEE, déclenchant l’exécution de la fonction distribuée à la demande d’un utilisateur
2.3. Réalisation de la fonction distribuée
L’exécution de notre fonction distribuée va nécessiter 4 classes :
- SpeedAverageFunction, représente la fonction à exécuter sur chacun des nœuds du cluster. Cette fonction récupère dans la partition locale toutes les vitesses instantanées pour un véhicule donné. Ces données sont transmises au SpeedAverageCollector via l’objet ResultSender.
- SpeedAverageCollector, doit collecter les résultats retournés par les différents nœuds du cluster (action 4 dans le schéma précédent).
- SpeedAverageResult, permet de stocker les résultats prétraités. C’est l’objet qui sera renvoyé par le collecteur au client.
- GemFireManager, récupère et fournit une instance de la région. Elle permet de déclencher l’exécution de notre fonction distribuée, en spécifiant en argument l’identifiant du véhicule dont la vitesse moyenne doit être calculé.
Détaillons tour à tour chacune de ces 4 classes.
2.3.1. SpeedAverageFunction
Cette classe contient le traitement a effectuer par chacun des data hosts auxquels elle sera soumise. Toute fonction distribuée doit implémenter les interfaces Function et Declarable, cette dernière interface permettant d’être déclarée au sein d’un descripteur XML (voir la partie déploiement). Ci-après, le code commenté de la classe SpeedAverageFunction.
import com.gemstone.gemfire.cache.Declarable;
import com.gemstone.gemfire.cache.Region;
import com.gemstone.gemfire.cache.execute.Function;
import com.gemstone.gemfire.cache.execute.FunctionContext;
import com.gemstone.gemfire.cache.execute.RegionFunctionContext;
import com.gemstone.gemfire.cache.execute.ResultSender;
import com.gemstone.gemfire.cache.partition.PartitionRegionHelper;
import com.gemstone.gemfire.cache.query.SelectResults;
import com.gemstone.gemfire.cache.query.TypeMismatchException;
import com.octo.rtf.ws.model.VehicleMessage;
public class SpeedAverageFunction implements Declarable, Function {
@Override
public void init(Properties props) {
// Distributed function name extracted from XML descriptor
functionName = props.getProperty("name");
}
@Override
public void execute(FunctionContext fc) {
RegionFunctionContext context = (RegionFunctionContext) fc;
// Get local region data
Region localRegion = PartitionRegionHelper.getLocalDataForContext(context);
// Get the result collector
ResultSender resultSender = context.getResultSender();
// Retrieve arguments
String[] args = (String[]) context.getArguments();
try {
// Execute the query
SelectResults queryResults = localRegion.query(formQuery(args));
// Extract the results
Map results = queryRouteAverage(queryResults);
for (String key : results.keySet()) {
Integer[] data = results.get(key);
// Send each result to the collector
resultSender.sendResult(new Object[] {key, data[0], data[1]});
}
resultSender.lastResult(null);
} catch (
}
@Override
public boolean hasResult() {
// Does the function return results ?
return true;
}
@Override
public boolean isHA() {
// Is the high availability option set ?
return false;
}
@Override
public boolean optimizeForWrite() {
// Does the function write results on region ?
return false;
}
}
2.3.2. SpeedAverageCollector
Cette classe implémente l’interface ResultCollector<T extends Serializable,S extends Serializable>. T correspond à l’objet en entrée, c’est à dire retourné par les data hosts lorsqu’ils récupèrent des données (dans le cas de notre SpeedAverageCollector, un tableau d’objet), et S correspond à l’objet en sortie, c’est à dire retourné au client (ici, un objet SpeedAverageResult).
Ci-après, le code commenté de la classe SpeedAverageCollector.
import com.gemstone.gemfire.cache.execute.FunctionException;
import com.gemstone.gemfire.cache.execute.ResultCollector;
import com.gemstone.gemfire.distributed.DistributedMember;
public class SpeedAverageCollector implements ResultCollector {
SpeedAverageResult sar = new SpeedAverageResult();
public SpeedAverageCollector() {}
@Override
public void addResult(DistributedMember memberID,
Object[] resultOfSingleExecution) {
// Executed when a member return a result
if (resultOfSingleExecution == null) return;
String type = (String) resultOfSingleExecution[0];
int value = (Integer) resultOfSingleExecution[1];
int weight = (Integer) resultOfSingleExecution[2];
sar.addResult(type, value, weight);
}
@Override
public void clearResults() {
// When the function is reexucted
sar = new SpeedAverageResult();
}
@Override
public void endResults() {
// When a member sends its last result
}
@Override
public SpeedAverageResult getResult() throws FunctionException {
// Return the result (blocks until the last result is sent)
return sar;
}
@Override
public SpeedAverageResult getResult(long timeout, TimeUnit unit)
throws FunctionException, InterruptedException {
// Returns the result (blocks until timeout)
return getResult();
}
}
2.3.3. SpeedAverageResult
Cette classe va contenir l’ensemble des résultats et leurs accesseurs. Elle doit implémenter l’interface Serializable afin de pouvoir transférée aux data hosts via le réseau. Ci-après, le code commenté de la classe SpeedAverageResult.
public class SpeedAverageResult implements Serializable {
private Map results;
public SpeedAverageResult() {
results = new HashMap();
}
public void addResult(String type, int value, int weight) {
if (!results.containsKey(type)) {
results.put(type, new Integer[] {value, weight});
} else {
Integer[] data = results.get(type);
data[0] += value;
data[1] += weight;
}
}
public Double getAverage() {
int sum = 0, num = 0;
for (String type : results.keySet()) {
Integer[] data = results.get(type);
sum += data[0];
num += data[1];
}
if (num == 0) return new Double(0);
else return (double) (sum / num);
}
public Map getAverageByHighway() {
Map result = new HashMap();
for (String type : results.keySet()) {
result.put(type, getAverageForHighway(type));
}
return result;
}
public Double getAverageForHighway(String type) {
Integer[] data = results.get(type);
return (double) (data[0] / data[1]);
}
}
2.3.4. GemFireManager
Cette classe va permettre de se connecter en tant que client au système distribué GemFire. Elle va récupérer et fournir une instance de la région qui permettra de stocker les messages de nos véhicules connectés. La méthode getSpeedAverageFromVin() permettra de déclencher l’exécution de la fonction distribuée sur notre région. Ci-après, le code de la classe GemFireManager
import com.gemstone.gemfire.cache.Region;
import com.gemstone.gemfire.cache.client.ClientCache;
import com.gemstone.gemfire.cache.client.ClientCacheFactory;
import com.gemstone.gemfire.cache.client.ClientRegionShortcut;
import com.gemstone.gemfire.cache.execute.Execution;
import com.gemstone.gemfire.cache.execute.FunctionService;
import com.octo.rtf.ws.model.VehicleMessage;
public class GemFireManager {
private static final String LOCATOR_IP = "192.168.56.101";
private static final int LOCATOR_PORT = 55221;
private static final String REGION_NAME = "VehicleMessageRegion";
private static final String FUNCTION_SPEEDAVERAGE = "SpeedAverage";
private static ClientCache cache;
private static Region region;
public GemFireManager() {
// Create a local client cache
cache = new ClientCacheFactory()
.addPoolLocator(LOCATOR_IP, LOCATOR_PORT)
.set("log-level", "error").create();
// Get the region
region = cache.createClientRegionFactory(ClientRegionShortcut.PROXY)
.create(REGION_NAME);
}
public SpeedAverageResult getSpeedAverageFromVin(String vin) {
Execution execution = FunctionService
.onRegion(region)
.withCollector(new SpeedAverageCollector())
.withArgs(new String[] {vin});
SpeedAverageCollector collector = (SpeedAverageCollector) execution
.execute(FUNCTION_SPEEDAVERAGE, true, false, false);
return collector.getResult();
}
}
2.4. Configuration et déploiement des composants
2.4.1. Définissons la région
La région que nous allons créer ici devra stocker l’ensemble des messages remontés par les véhicules. Ces messages contiennent des données brutes, parmi lesquels un timestamp, la vitesse instantanée et le type de route emprunté.
Pour définir cette région, utilisons un descripteur XML :
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE cache PUBLIC "-//GemStone Systems, Inc.//GemFire Declarative Caching 6.5//EN" "http://www.gemstone.com/dtd/cache6_5.dtd"> <cache> <region name="VehicleMessageRegion" refid="PARTITION"> <region-attributes> <value-constraint>com.octo.rtf.ws.model.VehicleMessage</value-constraint> </region-attributes> </region> <function-service> <function> <class-name>com.octo.rtf.ws.gemfire.SpeedAverageFunction</class-name> <parameter name="name"><string>SpeedAverage</string></parameter> </function> </function-service> </cache>
Le descripteur est plutôt explicite : nous définissons ici un cache contenant une région partitionnée nommée VehicleMessageRegion, dont la valeur sera un objet VehicleMessage. La clef sera une simple chaine de caractère (non spécifiée donc nature par défaut). Enfin nous spécifions une fonction exécutable au travers de son identifiant « SpeedAverage ».
2.4.2. Dépendances Java
Locator et CacheServer sont des processus Java indépendants. Afin d’être lancés, déclarons quelques variables d’environnement permettant de régler définitivement le problème des dépendances.
# VARIABLES GEMFIRE GF_JAVA=$JAVA_HOME/bin/java; export GF_JAVA PATH=$PATH:$JAVA_HOME/bin:$GEMFIRE/bin; export PATH GEMFIRE=/srv/GemFire6514 CLASSPATH=$GEMFIRE/lib/gemfire.jar:$GEMFIRE/lib/antlr.jar:$GEMFIRE/lib/gfSecurityImpl.jar:$CLASSPATH; export CLASSPATH
2.4.3. Initialisation du Locator
Afin de déployer notre système distribué GemFire, choisissons la méthode du locator (par opposition à la méthode multicast). Le locator est un processus à l’écoute d’un port, réalisant la coordination entre les différents membres du système distribué GemFire. Le Locator peut être respectivement lancé et arrêté au travers des commandes suivantes.
gemfire locator-stop -port=55221 -address=192.168.56.101 gemfire locator-start -port=55221 -address=192.168.56.101
2.4.4. Lancement des cacheserver
Pour fonctionner, un cacheserver a besoin d’un répertoire de travail dans lequel il persistera les données (si l’option est spécifiée) ainsi que les différents logs.
Démarrons deux cacheservers dans deux répertoires distincts.
mkdir ./server1 ./server2 cacheserver start locators=192.168.56.101[55221] mcast-port=0 cache-xml-file=.. /server.xml -server-bind-address=192.168.56.101 -server-port=0 -dir=./server1 cacheserver start locators=192.168.56.101[55221] mcast-port=0 cache-xml-file=../server.xml -server-bind-address=192.168.56.101 -server-port=0 -dir=./server2
Pour stopper ces deux cacheserver, il suffit d’utiliser les commandes suivantes
cacheserver stop -dir=./server1 cacheserver stop -dir=./server2
Le système est maintenant prêt à opérer. Pour voir un exemple du résultat, n’hésitez pas à consulter le screencast disponible dans la deuxième partie de l’article concernant le push web.
3. Conclusion
Nous avons pu constater au travers de cet article que :
- Les efforts à fournir pour déployer une telle architecture sont loin d’être insurmontables.
- L’exécution de fonctions distribuées est particulièrement simple à mettre en œuvre.
Les fonctions distribuées ne forment cependant qu’une partie de ce que propose GemFire. Le framework offre également d’autres outils, comme la propagation par deltas pour réduire la charge sur le réseau ou le mécanisme de « Continuous Querying » qui permet d’être notifié sur changement du résultat d’une requête ou de l’état d’une région…
Suggestion d'articles :




{kind=link}
{kind=link}
{kind=link}

L'absence de publicité dans les pages de XXI surprend. Nombre d'entre vous s'en félicitent bruyamment. Certains y voient même un geste altermondialiste. Comme souvent, la réalité est plus simple.
Le coût de réalisation d'un numéro est élevé, car « le journalisme debout », celui qui sort de son bureau, coûte cher. La manne publicitaire aurait pu alléger nos comptes et les vôtres. Mais elle ne tombe pas du ciel. Les annonceurs demandent de « cibler le public » et de développer le « rédactionnel contextuel », ce qui en novlangue marketing veut dire de créer des rubriques consacrées aux voyages, aux montres, aux voitures, aux sorties culturelles et aux produits high-tech. Autant de tranches « d'actu consommation » entre deux pages de publicité.
En passant à la moulinette de cette logique, XXI aurait perdu son âme et son objet. Notre projet se serait dilué. Le choix de la librairie s'est imposé, ce qui a radicalisé notre proposition initiale : une revue encore plus dense et entièrement financée par ses lecteurs.
Votre adhésion à ce principe simple et vieux comme le monde – payer pour un contenu qui a un coût - donne à réfléchir. Lorsqu'au XIXe siècle, Émile de Girardin a introduit pour la première fois la publicité dans un journal, le prix de vente de son quotidien diminua de moitié et ses ventes furent multipliées par deux. Le cercle était vertueux : la qualité du contenu attirait les lecteurs qui faisaient venir les annonceurs. Les tests montraient même qu'un journal sans publicité apparaissait moins sérieux que lorsqu'il était étincelant de pubs !
Au tournant des années 1990, la concurrence des autres médias - bouquets de chaînes télé, multiplication des stations de radio, explosion d'Internet – a atteint de plein fouet les titres d'information. Les annonceurs ont changé de supports. Pour les retenir à tout prix, une spirale dangereuse s'est enclenchée. Les impératifs des annonceurs pèsent désormais sur les rédactions. Le pouvoir a été conquis par les financiers pour qui les lecteurs sont des « infomateurs » (comprenez consommateurs d'info) et les articles « un produit » qui doit répondre aux « attentes ».
Le rapport de force penche désormais ouvertement du côté des annonceurs. Un journal se construit de plus en plus à partir de représentations illusoires : d'une part le lecteur fantasmé (de préférence gros consommateur, cadre et diplômé du supérieur) et d'autre part ses attentes supposées (extrapolations de chiffres de ventes, de nombre de clics et d'études diverses). Le journaliste est pris en tenaille entre ces deux constructions imaginaires, qui menacent de remplacer la seule boussole qui vaille : le réel, ce qu'il voit, ce qu'il comprend du monde.
Les rubriques et les dossiers spéciaux conçus pour les annonceurs pullulent. La diffusion est dopée aux scoops de quelques heures, aux « dossiers choc » répétitifs. Les luxueux cadeaux d'abonnement remplacent l'appétence pour le contenu. Une proportion non négligeable des journaux est jetée à la poubelle sans être sortis de leur emballage.
XXI pratique l'école buissonnière de la presse. 50 000 exemplaires chaque trimestre, même à 15 €, pèsent peu face aux machineries des grands médias. XXI est une revue à bas bruit, sous le radar. Mais nous avons la conviction que cette hirondelle annonce un autre printemps pour la presse, ce que confirme le succès de la revue 6 Mois, la sœur photographique de XXI. Le temps des médias de masse est révolu.
Celui du lien est en train de naître. Comptez sur nous pour le nourrir et le protéger.
Laurent Beccaria et Patrick de Saint-Exupéry
Lorsque l’on parle de dette, il est de coutume de dire que « l’État vit au dessus de ses moyens », que le modèle social français n’est plus soutenable, et qu’il faut donc réduire les dépenses.
Pourtant, la réalité est légèrement différente : sur 1 600 milliards de dette publique remboursée depuis 1974, environ 1 200 milliards d’euros ne sont constitués que des seuls intérêts.
L’effet « boule de neige » explique en grande partie ce phénomène. Afin de rembourser les intérêts, le Trésor fait « rouler » la dette, il émet de nouveaux emprunts pour rembourser ceux d’avant. Ce mécanisme est digne d’une chaîne de Ponzi : d’une part car cela alourdit toujours plus la charge de la dette jusqu’à la rendre insoutenable ; et d’autre part parce que cet accroissement de la dette nécessite que de nouveaux contributeurs rejoignent le système et mettent au pot à leur tour.
En réalité, hors paiement des intérêts, les budgets sont globalement à l’équilibre comme le montre le graphique ci dessous (issu du travail de André-Jacques Holbecq) :

Rembourser la dette, ce n’est donc pas payer en différé les dépenses d’éducation, de santé ou d’autres investissements. Payer la dette revient essentiellement aujourd’hui à donner de l’argent aux détenteurs des bons du Trésor français. Qui sont-ils ? En vrac, des banques, des assurances, les grosses fortunes, et également les détenteurs d’assurance vie. Notons aussi que, selon l’Agence France Trésor, environ 65% de la dette publique française est détenue par des investisseurs étrangers.

Rien d’étonnant à ce que les marchés soient rémunérés en prêtant leur capital. Mais rappelons tout de même que l’Etat n’a pas toujours eu besoin des marchés pour se financer.
Ce n’est qu’à partir de 1974, après adoption de la loi controversée dite « Pompidou-Giscard » que le gouvernement français s’est interdit d’emprunter gratuitement à la Banque de France.
A l’époque, l’idée de cette loi était de ne pas encourager les politiques dispendieuses (afin de limiter les risques d’inflation monétaire), en leur privant l’accès aux financements faciles de la banque centrale.
L’instauration d’un garde fou contre le clientèlisme est une bonne intention, mais son application fut en réalité plutôt désastreuse. L’effet boule de neige évoqué plus haut est en effet passé par là, faisant exploser la dette publique jusqu’à atteindre 85% du PIB aujourd’hui.
Revenir sur la loi de 1973 serait une bagatelle, si seulement son principe n’avait pas été repris par les traités européens, qui stipulent non seulement que la Banque centrale européenne ne peut pas octroyer des crédits aux États, mais également que la BCE doit tout mettre en oeuvre pour maintenir une inflation basse, à environ 2%. Pourtant, comme l’expliquent certains économistes tel Olivier Blanchard du FMI, un peu d’inflation ne ferait pas de mal aux économies européennes puisque cela ferait « fondre » la dette tout en dévaluant quelque peu l’euro, relançant ainsi les exportations.
L’ambiguïté du droit de la dette
Entre 2008 et 2009, le pourcentage de dette de la France est passé de 60 à 85% du PIB. Une grande partie de cette augmentation s’explique par les coûteux plans de relance des États pour faire face à la crise financière provoquée par les prises de risques inconsidérées des banques.
L’ironie de l’histoire, c’est que pour sauver la finance de la déroute, les États ont emprunté à ces mêmes acteurs financiers pour ensuite soutenir les banques et autres secteurs touchés.
Et pendant que l’on interdit à la BCE de donner un peu d’air aux démocraties en les finançant directement, celle-ci ne se prive pas de renflouer les banques à des taux incroyablement bas.

La dérive de la dette publique n’est pas seulement due au clientèlisme des politiques, ni même à la trop grande générosité de notre modèle social. Ces problèmes sont secondaires au regard de l’absurdité du système monétaire dont la dette publique est le résultat.
Ce système est dicté par des dogmes économiques dont les limites apparaissent aujourd’hui évidentes. Et pour reprendre le titre de l’excellent livre de André-Jacques Holbecq, la dette est une « affaire rentable »… pour les marchés financiers.
Trop longtemps ceux-ci ont pris pour acquis que les obligations souveraines étaient « sans risque » et aujourd’hui, ils se réveillent et, réalisant que ce n’est pas le cas, forcent les États à engager des réformes difficiles.
Une situation paradoxale : soit la dette est vraiment « sans risque », auquel cas le paiement d’une prime de risque est illégitime. Ou la dette souveraine serait « risquée », alors il est logique que des investisseurs essuient éventuellement des pertes.
Il y a toujours eu deux façons de se désendetter : la première consiste à ne pas payer ceux qui ont pris le risque de prêter leur argent ; la seconde, c’est l’austérité budgétaire, c’est à dire le sacrifice du peuple face aux marchés.
—
Photos FlickR ![]()
![]()
![]() yenna ;
yenna ; ![]()
![]() http://underclassrising.net.
http://underclassrising.net.
Graphiques : André-Jacques Holbecq.
 La liberté d'expression ne peut être réduite au fait de pouvoir s'exprimer, et ne serait rien sans le droit de lire...
La liberté d'expression ne peut être réduite au fait de pouvoir s'exprimer, et ne serait rien sans le droit de lire...
Cela fait 10 ans maintenant que, en tant que journaliste, je tente de documenter la montée en puissance de la société de surveillance, et donc des atteintes aux libertés, et à la vie privée. Mais je n'avais jamais pris conscience de l'importance de ce "droit de lire", pour reprendre le titre de la nouvelle de Richard Stallman, le pionnier des logiciels libres. Lorsque je l'avais lu, à la fin des années 1990, elle me semblait relever de la science-fiction. 10 ans plus tard, elle n'a jamais été autant d'actualité.
La lecture de Comment contourner la censure sur Internet, ouvrage mis en ligne cet été (et disponible en عربي, english, español, français, русский & Tiếng Việt), m'a démontré à quel point la liberté d'expression ne se résumait pas au fait de pouvoir s'exprimer : comment pourrait-on librement s'exprimer s'il est impossible, ou interdit, de librement s'informer ?
Ce travers de pensée relève probablement, pour le Français que je suis, de la déclaration des droits de l'homme et du citoyen de 1789 qui, dans son article XI, stipulait que "la libre communication des pensées et des opinions est un des droits les plus précieux de l’Homme" :
Tout Citoyen peut donc parler, écrire, imprimer librement, sauf à répondre de l’abus de cette liberté, dans les cas déterminés par la Loi.
Les auteurs de la Déclaration universelle des droits de l'Homme, adoptée par l’Assemblée générale des Nations unies le 10 décembre 1948 à Paris, avaient pourtant tout compris, eux qui précisaient, dans son article 19 que :
Tout individu a droit à la liberté d'opinion et d'expression, ce qui implique le droit de ne pas être inquiété pour ses opinions et celui de chercher, de recevoir et de répandre, sans considération de frontières, les informations et les idées par quelque moyen d'expression que ce soit.
Dans leur introduction, les auteurs de Comment contourner la censure sur Internet précisent, à ce titre, que l'intellectuel libanais Charles Habib Malik, qui fut l'un des rédacteurs de la Déclaration universelle des droits de l'homme, avait décrit de son adoption par l'ONU comme suit :
Je sais maintenant ce que mon gouvernement s'est engagé à promouvoir, viser et respecter. Je peux m'agiter contre mon gouvernement et, s'il ne parvient pas à respecter son engagement, j'aurai avec moi le monde entier pour me soutenir moralement et je le saurai.
Or, et comme le soulignent les auteurs du manuel :
Il y a 60 ans, lorsque ces mots ont été écrits, personne n'imaginait la façon dont le phénomène global qu'est Internet étendrait la capacité des gens à chercher, recevoir et transmettre des informations, pas seulement à travers les frontières, mais aussi à une vitesse hallucinante et sous des formes pouvant être copiées, éditées, manipulées, recombinées et partagées avec un petit nombre ou un large public, d’une manière fondamentalement différente des moyens de communication existants en 1948.
Ces derniers temps, j'ai été amené à croiser des fonctionnaires qui, travaillant dans des ministères, n'avaient pas le droit d'accéder à Facebook, Twitter, Youtube ou Dailymotion, et donc aux endroits où, précisément, les internautes se moquaient ouvertement de l'action de leurs ministres respectifs... J'ai aussi croisé des militaires dont l'accès au Net était très sévèrement limité, alors même que leur métier de communiquants reposait notamment sur leur capacité à se connecter...
Nombreux sont ceux qui, tant dans les services publics (administrations, écoles, bibliothèques, etc.) que dans les entreprises privées, n'ont pas le droit d'accéder à tels ou tels sites web, et sont donc interdits de s'informer, même et y compris lorsqu'il s'agit pourtant de emplir la mission qui leur a été confiée, sans parler de tous ces étudiants & élèves qui ne peuvent s'informer sur le cancer du sein ou le travail du cuir au motif que les mots-clefs "sein" & "cuir" relèveraient de la pornographie... sans oublier, bien sûr, tous ceux qui, internautes de pays moins démocratiques, voient leur Net encore plus censuré.
De fait, les nombreux trucs, astuces et techniques permettant de contourner la censure sur Internet sont d'autant moins l'apanage des seuls pays non-démocratiques que l'un des tous premiers sites web à oeuvrer en la matière, Peacefire.org, fut créé en 1996 par Bennett Haselton, un étudiant américain, pour expliquer comment contourner les "filtres parentaux"...
Faites donc tourner... ne serait-ce que parce que, et comme le rappellent les auteurs de Comment contourner la censure sur Internet, "Filtrer mène à surveiller" :
Ceci va des parents regardant par-dessus l'épaule de leurs enfants ou vérifiant les sites visités depuis leur ordinateur, aux sociétés surveillant les e-mails de leurs employés, en passant par les agences chargées de faire respecter la loi qui demandent des informations aux fournisseurs d'accès Internet, voire saisissent votre ordinateur comme preuve d'activités "indésirables".
La question reste donc aussi de savoir en quelle mesure votre fournisseur d'accès à l'internet (FAI), votre employeur, prestataire de service (y compris public, en bibliothèque, université ou école) pourrait d'aventure estimer que vos lectures seraient "indésirables"...
A toutes fins utiles, et parce que cela montre à quel point des gens motivés peuvent, en peu de temps & à peu de frais, sinon changer la face du monde, tout du moins contribuer notablement à en infléchir les paradigmes, il n'est pas anodin de noter que cet ouvrage, et mode d'emploi, a été écrit, en mode booksprint ("session de travail intensif autour d'un objectif défini, dans un temps limité"), par 8 personnes qui ont "travaillé ensemble de manière intensive pendant 5 jours dans les belles montagnes de l'État de New York aux États-Unis" (voir la vidéo)... #respect
Vous pouvez également suivre leurs actualités via leur profil Facebook, leur compte Twitter, ou encore voir leurs vidéos, traduites en français sur dotSub, aini que le site contournerlacensure.net/ que les traducteurs de la version en français ont monté pour l'occasion (et qu'ils en soient remerciés).
& si vous vous intéressez vraiment à la sécurité informatique, je ne saurais que trop vous conseiller de lire ce "Guide d’autodéfense numérique", très complet et même tellement précis que, pour l'instant, il se focalise essentiellement sur le fait de sécuriser son ordinateur... "non connecté".
D'un point de vue plus pratique, vous pouvez également opter pour Tails, un Live-CD ou live USB (autrement dit : un système d'exploitation sur lequel vous pouvez démarrer depuis votre lecteur de CD-Rom, ou depuis une clef USB, et qui vous permet d'utiliser n'importe quel ordinateur sans y laisser de traces) et dont le but est explicitement de "préserver votre vie privée et anonymat".
Voir aussi :
Il est interdit d’interdire (le Net)
Un fichier de 45M de « gens honnêtes »
Pourquoi le FBI aide-t-il les terroristes?
Pour en finir avec la culture de la peur
Peut-on obliger les policiers à violer la loi ?
Le gouvernement Sarkozy veut censurer internet
10 ans après, à quoi ont servi les lois antiterroristes ?
Pour une entreprise, le cloud computing est une petite révolution dans la façon de considérer l'informatique mais c'est aussi une nouvelle source de soucis. Un peu comme les infections qui se nichent entre les doigts de pieds : Elles apparaissent, on les soigne, on pense avoir gagné et peu temps après elles sont de nouveau là...
Pour une entreprise, les applications en mode cloud computing c'est peu ou prou la même chose que ces mycoses ou autres champignons : Les employés souscrivent d'eux-mêmes à des services cloud, la direction sécurité n'étant pas mise dans la boucle ; au contraire cette dernière est soigneusement oubliée : Il ne faudrait pas qu'elle puisse fourrer son nez dans ce qui ne la regarde pas.
Selon Doug Toombs, Analyste Senior chez Tier1 Research, il est nécessaire d'accompagner ce changement car il est trop tard pour l'enrailler.
Les motivations profondes : Rapidité de mise en oeuvre, documentation et coûts
Pour les directions métiers, l'amélioration de leur productivité et de leur agilité passe par une plus grande réactivité dans la mise en oeuvre des moyens et systèmes nécessaires pour atteindre leurs objectifs. Depuis plusiseurs années (voire décennies) les directions informatiques les assomment de délais improbable allant de pair avec des coûts dignent du meilleur escroc.
Une autre raison réside dans le fait que des services de cloud externes n'ont pas d'équivalents en interne ou encore que ceux-ci sont tout simplement bien mieux documentés et clairs que leurs versions internes. Car oui, certains services en internes sont parfois bien mais la documentation est souvent un peu trop basique, pas à jour voir quasiment obsolète.... et gare à celui qui osera dire tout haut ce que tout le monde pense tout bas !
Avant le cloud, les directions métiers étaient ; excusez-moi de l'expression ; "de la baise". Avec le cloud computing elles ont désormais le choix : les directions informatiques doivent donc s'adapter et évoluer ; les directions sécurité aussi.
Un état de fait, une tendance qu'il n'est pas possible d'arrêter
Souscrire à un service cloud est facile et rapide : il suffit d'un accès Internet et de sortir sa carte bancaire corporate. Les services cloud qui sont les premiers sur la liste sont ceux de type SaaS (Software as a Service), les PaaS (Platform as a Service) ou même ceux de type IaaS (Infrastructure as a Service).
A moins de couper les accès Internet (totalement irréaliste) ou de filtrer l'accès à ceux-ci (à quand une catégorie "Cloud Services providers" dans les systèmes de filtrage d'URL ?), la tendance est à un élargissement du nombre de prestataires de services informatiques. Les directions informatique et sécurité sont donc tenues ; si elles veulent rester en place et continuer à être reconnues ; de se mettre au gôut du jour et d'accompagner ce changement.
Accompagner pour préparer l'avenir et anticiper
Une direction informatique, assistée de la direction sécurité, doit donc faire la part des choses et guider son organisation afin de l'accompagner vers cette transition vers le cloud computing. Sans chercher à brosser dans le sens du poil, mon avis est que les directions sécurité possèdent une plus grande pratique de "l'accompagnement" des projets que les direction informatiques.
Oui, l'utilisation inconsidérée de services en mode cloud peut être dangereux pour une entreprise. Illustration en deux points : La conformité et la continuité.
Données personnelles
Une entreprise française manipulant des données personnelles est tenue d'assurer la sécurité de ces données et celles-ci doivent rester dans le giron de l'espace européen (ou sur le sol d'un pays reconnu comme étant "suffisamment protecteur"). Tout le monde n'est pas au fait de ces aspects réglementaires (directive Européenne 95/46/EC), une direction sécurité est donc tout à fait légitime pour guider le choix (sans s'y opposer ou forcément chercher à placer d'autres solutions) vers un fournisseur en mesure de répondre à ce besoin de conserver les données dans une liste de pays pré-établie.
De la même façon, il conviendra de s'assurer que les équipes de support techniques du prestataires sont bien localisées dans des pays connus. Car oui, si les données doivent être localisées dans des datacenters précis, les personnes accédant à distance à ces mêmes données doivent aussi l'être.
Dans le cas conytraire, la loi indique que le client final doit être informé que des données personnelles le concernant sont amenées à quitter la zone europe (ou un pays "reconnu") et cela doit être stipulé dans le contrat de service.
Continuité
Utiliser des services comme le PaaS pour des applicatifs ou exécuter des machines virtuelles dans le cloud est souvent motivié pour une rapidité de mise en place, répondre à une charge ponctuelle ou encore accélérer les développements ou tests.
Dans chacun de ces contextes d'utlisation de services cloud, il est critique d'assurer que ces activités peuvent être déplacées vers un autre fournisseur que celui initialement choisi (par exemple si celui viendrait à cesser ses activités). De la même façon, une société peut initier un projet grâce aux services cloud d'un tiers pour ensuite ré-internaliser celui-ci vers un cloud privé ou communautaire.
Réversibilité
Si ces questions relatives à réversibilité n'ont pas été abordées et instruites lors de la phase initiale de souscription du service le retour en arrière pourrait prohibitif voir même dans certains cas impossible.
Dans tous les cas, il est important de s'assurer que les données peut être effectivement récupérées sous un format ré-utilisable. Pour de l'IaaS, cela passe via la possibilité de récupérer des sauvegardes complètes de ses machines virtuelles (sous un format spécifique à l'hyperviseur ou encore sous forme de fichiers OVF).
Dans le domaine du PaaS, le sujet n'est pas neuf, les récents échanges de mots entre Google et Joyent ("Google Cloud Services Criticized by Jason Hoffman", 21 Aout 2011) au sujet de Big-Table sont un bon exemple du besoin d'utiliser des techniques standardisées (ou tout du moins non propriétaires) car sinon c'est le "syndrome d'enfermement" assuré.
Souplesse et accompagnement
La balle est dans le camp des directions informatiques et sécurité : Le cloud computing est là et sera de plus en présent car elles trouvent dans ce modèle une agilité qui leur est nécessaire. Le proverbe Japonais "La neige ne brise jamais les branches du saule" illustre bien le comportement à adopter : Souplesse et accompagnement sont les clefs d'une transition vers le cloud computing.
Parcourez notre dossier climat et couche d'ozone
Alors que l'on considérait que le problème du trou de la couche...
Hier, Apple a annoncé la sortie de son nouveau mobile, et ce sont les amateurs de photos qui vont être ravis. Cet iPhone 4S n’a rien de nouveau en apparence, mais l’appareil photo a été revu par Apple.
Le capteur de l’iPhone passe à 8 Mégapixels (on le sait, la course aux mégapixels n’est pas nouvelle) pour donner un fichier de 3264 × 2448. Mais c’est surtout un capteur « 73% plus lumineux » que l’iPhone 4 aux dires d’Apple. Ceci est rendu possible par l’utilisation d’un capteur rétro-éclairé, et permettra de faciliter la prise de vue dans un environnement à faible lumière.

Apple annonce également que son capteur sera plus rapide pour prendre des photos, jusqu’à 1/3x plus rapide. L’appareil est aussi désormais stabilisé, mais ce n’est pas une stabilisation mécanique, mais plutôt logicielle, grâce à la nouvelle puce A5.
Au niveau de l’objectif, le mobile à la pomme s’améliore encore en passant d’un 30 mm f/2.8 à un objectif encore plus grand angle (24 mm?) à f/2.4.
Voici quatres photos prises avec un iPhone 4S. Cliquez dessus pour obtenir la version 100%. (Source)




On attend bien entendu des tests pour se faire une meilleure opinion.



