 Liste de partage de Grorico
Liste de partage de Grorico
![]()
![]()
- K750 : Le clavier sans fil solaire de chez Logitech
- Innovation : Deux nouvelles méthodes pour recharger son ordinateur portable.
- Une table solaire pour recharger vos périphériques mobile sans fil
- Un système portable et déroulable d’alimentation à énergie solaire
Solar Sinter : Une imprimante 3D qui transforme le sable en verre
Source : technabob.com
Article original publié sur Semageek® | Actualités High Tech, Robot, Électronique, DIY et Arduino..

Mozilla s’intéresse depuis longtemps à la gestion de l'identité numérique et aux moyens de donner aux utilisateurs davantage de contrôle sur leur identité en ligne, notamment au travers de leur navigateur. Ils portent ces jours-ci leurs efforts sur un point particulier: simplifier l'identification auprès de sites Web. Le projet "verified email" permet de le faire au moyen d'une simple adresse de messagerie électronique, sans mot de passe.
Le projet "verified email" se compose d'un protocole, en cours de définition, de services hébergés par Mozilla pour fournir les outils utilisés par le protocole en attendant qu'ils se diffusent plus largement, et bien sûr d'implémentations du protocole dans des clients, notamment Firefox.
mise à jour du 15 juillet : le projet s'appelle à présent BrowserID, a un site web et la liste de discussion a été réparée.
Nos adresses de courriel sont les clés de nos identités numériques
Plutôt que d'inventerdemander aux internautes de se
créer[1] un nouvel identifiant, comme c'est
souvent le cas avec OpenID, l'idée est d'utiliser l'identifiant le plus
courant et le mieux compris: l'adresse de messagerie électronique, le mail. La
majorité des internautes est consciente que l'adresse "alice@site.com"
représente une personne (ou un groupe) connue du site site.com, qu'elle
identifie une personne physique. Les adresses mail ont de plus quelques
caractéristiques intéressantes: c'est un système distribué, n'importe qui peut
créer son propre serveur et gérer son adresse, une personne peut avoir autant
d'adresses qu'elle veut, on peut aisément créer des pseudonymes, etc. Toutes
ces caractéristiques permettent de répondre à la plupart des cas d'utilisation
d'un identifiant qui offre aux internautes liberté et fiabilité.
Beaucoup de sites utilisent déjà l'adresse mail pour identifier leurs utilisateurs. A partir du moment où ils fournissent une fonction pour récupérer l'accès à son compte via l'envoi d'un courrier, ils disent implicitement "ce compte utilisateur appartient à la personne qui contrôle cette adresse mail". L'adresse mail est donc déjà largement utilisée comme réceptacle de l'identité en ligne. L'idée de Verified email est de pousser plus loin cette assertion, de garantir qu'une adresse mail suffit à identifier une personne.
Verified email, comment ça marche ???
Le principe est le suivant:
- l'utilisateur enregistre dans son navigateur ses adresses mails;
- le navigateur vérifie auprès des serveur de messagerie que ces adresses sont bien contrôlées par l'utilisateur;
- lorsque l'utilisateur se connecte à un site en utilisant une de ces adresses, le navigateur fournit au site les moyens de vérifier son identité;
Le navigateur a un rôle central dans ce processus. Et ça tombe bien, puisque c'est l'élément sur lequel l'utilisateur a le plus de contrôle. Ses identités et les moyens de les contrôler ne sont pas stockées en ligne, mais en grande partie dans son navigateur.
Sous le capot
Le protocole utilise de la cryptographie asymétrique, comme le fait par exemple PGP. Très schématiquement, celle-ci repose sur l'utilisation d'une clé en deux parties, chaque partie permettant de défaire ce que l'autre a fait. Le propriétaire de la clé conserve une de ces parties, la clé secrète et diffuse largement l'autre, la clé publique. Cela permet de chiffrer des communications, mais également de les signer, de garantir leur origine et leur intégrité. Par exemple, pour signer un message, le logiciel calcule une somme de contrôle du message et la chiffre avec ma clé privée. Les destinataires déchiffrent la signature avec ma clé publique et vérifient que la somme de contrôle est exacte. Si oui, cela signifiera que la signature a bien été effectuée avec ma clé privée (et que le message n'a pas été altéré). S'ils ont pu par un autre biais vérifier le lien entre ma clé publique et moi, ils ont la certitude que le suis bien l'auteur du message.
Verified email utilise les mêmes technologies. Lorsque je déclare au navigateur une de mes adresses mails, celui-ci crée une paire de clés et envoie la clé publique au serveur de mail. Si celui-ci m'a identifié (par exemple parce que je suis actuellement connecté au webmail), il associe cette clé publique à mon compte.
Lorsque je me connecte à un site tiers compatible, mon navigateur lui envoie un message contenant diverses informations dont l'adresse mail avec laquelle je veux d'identifier. Ce message est signé avec ma clé privée. Le site récupère alors la clé publique auprès du serveur de mail et vérifie la signature. Si elle est correcte, il a ainsi la preuve que je suis bien la personne connue du serveur de mail sous cette identité.
Plus en détail
Le brouillon de spécification propose un exemple d'implémentation: pour enregistrer une adresse dans mon navigateur, il me faut d'abord me connecter au site Web de mon prestataire de messagerie, puis aller sur une page contenant un script qui indique au navigateur l'adresse à enregistrer et la méthode pour publier la clé publique. Par exemple un appel de ce type:
navigator.id.saveVerifiedAddress( "bob@clochix.net", <callback>);
Le navigateur va créer une paire de clés pour l'adresse "bob@clochix.net" et envoyer la clé publique au serveur via la fonction de callback. Le serveur associe la clé publique à l'adresse mail. Il peut enregistrer plusieurs clés publiques pour chaque adresse, me permettant de déclarer mon adresse dans autant de périphériques que je le souhaite.
Si un site est compatible avec le protocole, sa page de connexion contient un script qui l'indique au navigateur et décrit la méthode pour envoyer une demande. Le butineur affiche alors un bouton de connexion directement dans son interface (probablement une fenêtre comme celle proposant actuellement d'enregistrer un mot de passe). Je peux sélectionner parmi les adresses enregistrées dans le brouteur celle avec laquelle je veux me connecter. Le navigateur crée un message contenant cette adresse, des informations complémentaires que j'y ai associées et une date d'expiration, signe le message avec la clé privée de l'adresse, et envoie le tout au serveur. Le serveur extrait l'adresse du message, découvre le serveur qui fait autorité pour cette adresse, récupère la clé publique de l'adresse et vérifie la signature. Le protocole ne précise pas comment découvrir le serveur qui fait autorité, mais suggère d'utiliser par exemple WebFinger.
Dans ce scénario, plus besoin de mot de passe pour me connecter au site: mon adresse mail suffit à prouver qui je suis.
Le navigateur peut proposer d'autres fonctions pour simplifier la gestion des connexions, comme par exemple mémoriser l'adresse utilisée pour se connecter à chaque site. Il pourrait également permettre à l'utilisateur de se connecter à un site avec plusieurs adresses différentes. Il devrait alors fournir une interface pour terminer la session sur le serveur et ouvrir une nouvelle session avec une nouvelle identité.
Déployer
La mise en œuvre de ce protocole risque de ne pas être simple, car elle implique de nombreux acteurs: les gestionnaires des serveurs de messagerie, et ceux des services en ligne. Les premiers doivent permettre d'associer des clés publiques à chaque adresse qu'ils gèrent, les second mettre en place les mécanismes parfois un peu complexe de découverte du serveur faisant autorité et de vérification de la signature. Pour que ces difficultés ne soient pas rédhibitoires, Mozilla propose des solutions alternatives, avec des "autorités secondaires" et des prestataires de vérification.
Imaginons qu'une de mes identités soit liée à une compte mail hébergé chez Gandi, qui n'a pas encore implémenté le protocole. Je décide d'utiliser comme tiers de confiance un site fourni par Mozilla. J'indique à Mozilla l'adresse que je veux valider, Mozilla m'envoie un mail contenant un lien vers son site. Si je clique sur le lien, cela prouve que j'ai accès à l'adresse, donc qu'elle m'identifie. Mozilla déclenche la procédure de création de clé avec mon navigateur, et stocke la clé publique de l'adresse. Le navigateur sait que la clé publique est hébergée par un tiers de confiance, l'autorité secondaire. Lorsque je veux utiliser cette adresse pour me connecter à un site, mon navigateur indique dans le message signé le tiers à contacter pour obtenir la clé publique. Au site de décider s'il accepte également de faire confiance à ce tiers. (attention, si le site fait confiance à n'importe quel tiers, tout le mécanisme s'effondre).
Mozilla envisage de fournir une telle autorité secondaire, en complément à son service de synchronisation de profils (Sync). Les utilisateurs pourraient enregistrer toutes leurs adresses auprès de ce service, et on peut espérer que du fait de la réputation de Mozilla, il soit reconnu comme autorité secondaire par de nombreux sites. Le protocole pourrait ainsi être rapidement déployé, même si les prestataires de messagerie de l'implémentent pas. Le service pourrait également offrir une API pour vérifier une adresse, simplifiant ainsi l'implémentation par les sites: ceux-ci n'auraient qu'à envoyer le message signé du navigateur au service qui se chargerait de vérifier la signature. L'implémentation de l'authentification par adresse vérifiée serait ainsi des plus simples: un peu de JavaScript pour récupérer l'adresse, et un appel à un service web pour la vérifier.
Un autre point risquant de ralentir le déploiement de cette solution est sa disponibilité dans les clients. Même si, rêvons, tous les fondeurs de navigateurs décidaient d'implémenter le protocole, des années s'écouleraient sans doute avant qu'une majorité d'internautes dispose d'un navigateur compatible. Mozilla propose donc un autre contournement, sous la forme d'une version HTML du client. C'est dans ce cas le site de l'autorité secondaire qui gère les adresses mail de l'utilisateur à la place du navigateur, et certifie son identité auprès des sites tiers. Le tout utilise toute la bonne vieille artillerie de la communication entre site en vieil HTML, iframes et compagnie, comme le service de connexion multi-sites d'un silo bien connu. Une démonstration est déjà disponible qui permet de se connecter à un site fictionnel via une autorité secondaire. Les sources de la démo sont sur Github et utilisent Node.js, ce qui me donne bien envie d'aller y regarder de plus près.
Travail en cours
La proposition de spécification n'est pas encore mature, et bien des questions restent ouvertes. Par exemple, un inconvénient du système est que les prestataires de messagerie sont contactés à chaque fois que je veux me connecter à un site, donc connaissent les sites auxquels je me connecte. Le protocole propose un mécanisme alternatif pour remédier à ce soucis: lorsque le navigateur lui envoie la clé publique associée à l'adresse, le prestataire de messagerie signe cette clé avec la clé privée du serveur et ré-expédie le tout au navigateur, qui stocke donc également la clé publique associée à l'adresse, signée par la clé privée du serveur. Lors de la connexion à un site tiers, il envoie directement la clé publique signée. Le site tiers récupère alors la clé publique du serveur de messagerie et l'utilise pour vérifier la signature. Si la signature est correcte, cela suffit à prouver que le serveur de messagerie a bien validé l'association entre l'adresse et cette clé publique.
Une autre faille du système est que les administrateurs d'un serveur ont généralement accès à tous les messages, et pourraient donc usurper l'identité de n'importe lequel de leurs utilisateurs. Rien n'est pour l'instant prévu sur ce point, qui est d'ailleurs commun à la plupart des services d'identification en ligne.
Il reste donc pas mal de travail pour finaliser la spécification, et je pense que tous les avis seront les bienvenus. J'ai essayé de résumer le protocole, mais le brouillon de spécification entre bien évidemment beaucoup plus dans les détails, je vous encourage vivement à aller le lire.
En conclusion
Verified Email essaie de bâtir en tirant les leçons du relatif échec de précédentes tentatives similaires, comme OpenID. Son maître mot est la simplicité: simplicité et transparence du processus pour l'utilisateur, simplicité de l'implémentation pour les éditeurs de sites, via les autorités secondaires et les services de vérification.
Outre l'utilisation d'un identifiant bien connu comme l'adresse mail, un des avantages de cette solution est de mettre le navigateur au centre du dispositif. Le navigateur est quelque chose que l'utilisateur peut contrôler (enfin s'il utilise un logiciel libre et auquel il fait confiance), donc si le protocole est largement adopté, c'est l'internaute qui en bénéficiera en ayant un meilleur contrôle sur ses identités numériques. Par ailleurs, le navigateur pourra offrir de nombreuses fonctionnalités complémentaires d'aide à la gestion des identités. Il pourrait par exemple afficher des informations sur la politique de confidentialité des sites (obtenues via P3P), créer automatiquement des adresses temporaires… Je fais confiance à la créativité des développeurs d'extensions pour inventer ces fonctions.
Pour résumer, Verified email, c'est donc:
- un mécanisme permettant de s'identifier auprès de sites tiers avec son adresse mail, sans avoir besoin de mot de passe;
- ce mécanisme sera directement intégré dans les navigateurs;
- l'ensemble permet de gérer ses identités de manière décentralisés;
- pas besoin d'attendre une implémentation dans tous les navigateurs et par tous les serveurs de mail, le protocole est utilisable dès aujourd'hui (bon, demain) via un client en HTML et des autorités secondaires;
Le projet lui-même comporte six étapes, vous pouvez vous référer au wiki pour suivre leur évolution :
- la spécification du protocole (je ne sais pas s'il a été prévu de le soumettre à une autorité de normalisation type W3C ou IETF);
- l'implémentation de trois versions du client: dans les versions fixes et mobile de Firefox, et sous forme d'application Web;
- la mise en place d'un serveur d'autorité secondaire;
- le développement d'une interface Web pour ce serveur;
Sources de ce billet
- les projets de gestion d'identité en cours chez Mozilla: https://wiki.mozilla.org/Identity;
- la version originale de la proposition de spécification, sur le blog de Mike Hanson, et ses dernières évolutions;
- des maquettes d'un gestionnaire de comptes et une démonstration interactive|http://people.mozilla.com/~faaborg/files/projects/firefoxAccount/], mais je ne saurais dire si c'est lié à Verified email / MozillaID, ou si c'est encore un autre projet.
Appendice: un peu d'histoire
Mozilla s'intéresse depuis longtemps à la question de l'identité numérique. Les Labs avaient lancé au printemps 2010 une réflexion sur la gestion de ses identités en ligne. Deux extensions prospectives avaient vu le jour dans le cadre de ce programme:
- un gestionnaire de comptes pour simplifier la gestion de ses comptes sur différents sites;
- un gestionnaire de contacts;
Les deux étaient des expériences destinées à explorer des pistes, et ont été assez rapidement abandonnées.
C'est une des caractéristiques de Labs, lancer des projets enthousiasmants
et les abandonner après quelques itérations. Ce sont sans doute les lois du
genre de la R&D, mais c'est toujours un peu frustrant d'avoir aperçu à quoi
pourrait ressembler le futur et de voir la porte se refermer. Elle ne s'est
cependant pas complètement refermée, du moins sur le gestionnaire de comptes,
car la troisième
priorité de Firefox pour 2011 est d'Expand the Open Web Platform to
include Apps, Social and Identity
, notamment en créant des systèmes ouverts
de gestion de l'identité et des interactions sociales. A vrai dire, dès la
mi-2010, un
ticket avait été créé pour intégrer la première extension dans Firefox 4.
Les travaux ont été bon train durant quelques mois, avant une soudaine
inactivité, le report de la fonctionnalité dans Firefox 5, puis finalement
l'annonce de son abandon, sans plus d'explications. C'est en cherchant des
informations sur Dan Mills, qui avait fermé le ticket en indiquant juste un
changement d'orientation, que j'ai fini par tomber sur MozillaID / Verified
Email.
Si je fait ce petit rappel historique, c'est en guise de mise en garde: souvent Mozilla varie, bien fol qui s'enthousiasme trop vite. Je n'ai pas réussi à trouver d'informations permettant de deviner si ce nouveau projet a de l'avenir ou va finir comme tant d'autres dans les poubelles du centre de recherche de la Fondation. Les commentaires de ce billet sont ouverts à toute précision, et je tâcherai de vous tenir informés des évolutions du projet.
Découvrir Verified email a en tout cas été une bonne surprise pour moi. Cela m'a redonné espoir que l'innovation pour Mozilla ne se borne pas à courir derrière la concurrence (je ne suis pas près de digérer le ticket 665580), mais continue à essayer d'inventer de nouveaux outils pour donner plus de pouvoir à l'utilisateur. Ouf, Momo rules toujours.
Notes
[1] reformulation de la phrase après la remarque de Stéphane Bortzmeyer
 MaJ : la proposition de loi a donc été adoptée, en première lecture, en présence de 7 députés de la majorité, et de 4 députés de l'opposition; comme le titre PCInpact, 11 députés votent le fichage de 45 millions d'honnêtes gens...
MaJ : la proposition de loi a donc été adoptée, en première lecture, en présence de 7 députés de la majorité, et de 4 députés de l'opposition; comme le titre PCInpact, 11 députés votent le fichage de 45 millions d'honnêtes gens...
L'Assemblée nationale va débattre, ce jeudi 7 juillet, une proposition de loi sur la protection de l'identité, dans un hémicycle fort de 11 députés . Objectifs : ajouter à la future carte d'identité une puce électronique régalienne, pour être identifié auprès des services de sécurité, une deuxième puce facultative pour les services et le commerce électronique, mais aussi et surtout créer une base de données centralisée des empreintes digitales et photographies de leurs titulaires.
Le rapporteur de la proposition de loi a ainsi qualifié de “fichier des gens honnêtes” (sic) cette base de données qui répertoriera les noms, prénoms, sexe, dates et lieux de naissance, adresses, tailles et couleurs des yeux, empreintes digitales et photographies de 45 millions de Français voire, à terme, de l’ensemble de la population.
Dans le même temps, le gouvernement britannique a décidé, lui, d'abandonner son projet de carte d'identité, parce qu'attentatoire aux libertés, et le gouvernement néerlandais vient d'annoncer qu'il allait cesser de rendre obligatoires la prise d'empreintes digitales de ceux qui réclament une carte d'identité, et de détruire, à terme, la base de données, au vu du nombre trop élevé d'erreurs rencontrées…
Ce sera le premier « fichier des gens honnêtes »
Le nombre de fichiers policiers a augmenté de 169% depuis l'arrivée de Nicolas Sarkozy au ministère de l'Intérieur, en 2002 : plus de la moitié des 70 fichiers recensés ont été créés sous son autorité. Dans le même temps, le Parlement a voté pas moins de 42 lois sécuritaires. On aurait pu penser qu'à ce train-là, le problème de l'insécurité devrait avoir été au moins partiellement réglé.
Mais tel n'est pas l'avis de la Cour des Comptes, qui vient de publier un rapport particulièrement sévère sur les tripatouillages statistiques du ministère de l'Intérieur. Mais tel n'est pas non plus l'avis du gouvernement, qui continue à vouloir sévir dans le sécuritaire.
Prenez, par exemple, l'usurpation d'identité. Le code de la route, le code de procédure pénale et le code des transports comprenaient d'ores et déjà différentes mesures réprimant les infractions ayant trait à la fourniture d'identités imaginaires ou à l'usurpation d'identité. Et la LOPPSI II a, précisément, en mars dernier, créé un délit d'usurpation d'identité... mais ça n'était pas encore assez.
Officiellement, la proposition de loi sur la protection de l'identité, adoptée en première lecture au Sénat et à l'Assemblée, vise à lutter contre l'usurpation d'identité, un phénomène croissant mais qui, d'après la police, ne représenterait pas plus de 15 000 faits constatés par année (voir Vers un fichage généralisé des "honnêtes gens", mon enquête à ce sujet sur OWNI). Comme l'a rappelé François Pillet, rapporteur de la loi au Sénat, "pour atteindre l’objectif du texte, il faut une base centralisant les données" :
Ce sera le premier « fichier des gens honnêtes ».
Ce fichier n’a pas d’équivalent. Toutes les personnes auditionnées ont mis en garde, plus ou moins expressément, contre son usage à d’autres fins que la lutte contre l’usurpation d’identité, ce qui présenterait des risques pour les libertés publiques.
De fait, le Conseil d'État, la CNIL et la Cour européenne des droits de l'homme se sont d'ores et déjà prononcés contre ce type de fichage biométrique généralisé de personnes innocentes de tout crime ou délit, pour la simple et bonne raison qu'il s'agit là d'une violation manifeste de la convention européenne de sauvegarde des droits de l’homme et des libertés fondamentales, de la convention sur la protection des données du Conseil de l’Europe, et de la loi informatique et libertés.
C'est même précisément ce pour quoi, estime l'opposition, le gouvernement n'a pas rédigé de projet de loi à ce sujet, afin d'éviter d'avoir à saisir le Conseil d'État et la CNIL, et préféré demander à un sénateur de rédiger cette proposition de loi.
Au Sénat, François Pillet avait tenté d'empêcher tout détournement de finalité de la base de donnée, afin d'exclure, notamment, son utilisation en matière de police judiciaire, et faire de sorte qu'il soit techniquement impossible de s'en servir pour identifier un individu à partir de ses empreintes digitales ou de sa photographie :
Nous ne voulons pas laisser derrière nous une bombe : c’est pourquoi nous créons un fichier qui ne peut être modifié.
Mais le gouvernement, tout comme Philippe Goujon, le rapporteur de la proposition de loi à l'Assemblée, s'y sont fermement opposés, arguant du fait qu'il serait dommage de ne pas profiter de l'occasion pour permettre à la police, sur réquisition judiciaire, de se servir de la base de données en matière de recherche criminelle…
Pour Delphine Batho, la députée PS spécialiste des fichiers policiers, "le véritable objectif de ce texte" n'est donc pas la lutte contre l'usurpation d'identité, mais "le fichage biométrique de la totalité de la population à des fins de lutte contre la délinquance" :
Il existe un fichier permettant d’identifier les fraudeurs : le fichier automatisé des empreintes digitales (FAED), qui recense 3 millions d’individus, soit 5 % de la population, et qui a permis de détecter 61 273 usurpations d’identité. Cet outil me semble suffisant.
Les auteurs de cette proposition de loi estiment, pour résumer, que pour détecter un fraudeur, il faut ficher tout le monde.
De la convivialité des technologies de contrôle
L'autre véritable objectif de la loi, c'est de soutenir les industriels de l'identification biométrique, dont les leaders sont français, comme l'a reconnu Jean-René Lecerf, l'auteur de la proposition de loi, en déclarant sobrement que "les entreprises françaises sont en pointe mais elles ne vendent rien en France, ce qui les pénalise à l’exportation par rapport aux concurrents américains" (voir Fichons bien, fichons français, deuxième partie de mon enquête).
Philippe Goujon a été encore plus clair, ne cherchant même pas à cacher qu'il s'agit là d'une opération de patriotisme économique résultant d'une campagne de lobbying :
Comme les industriels du secteur, regroupés au sein du groupement professionnel des industries de composants et de systèmes électroniques (GIXEL), l’ont souligné au cours de leur audition, l’industrie française est particulièrement performante en la matière : les principales entreprises mondiales du secteur sont françaises, dont 3 des 5 leaders mondiaux des technologies de la carte à puce, emploient plusieurs dizaines de milliers de salariés très qualifiés et réalisent 90 % de leur chiffre d’affaires à l’exportation.
Dans ce contexte, le choix de la France d’une carte nationale d’identité électronique serait un signal fort en faveur de notre industrie.
MaJ : l'AFP indique que les versions adoptées par le Sénat et l'Assemblée n'étant pas analogues, il faudra que soit désignée une commission mixte paritaire (CMP) pour établir un texte de compromis. Celle-ci ne sera probablement désignée qu'au cours de la prochaine session parlementaire, à la rentrée.
Quand le GIXEL proposait de ficher les enfants dès l'école maternelle pour leur "faire accepter les technologies de surveillance et de contrôle"
Le GIXEL s'était déjà fait connaître, en 2004, pour avoir proposé de "faire accepter la biométrie, la vidéosurveillance et les contrôles", hélas "souvent vécue dans nos sociétés démocratiques comme une atteinte aux libertés individuelles" par des opérations soutenues par les pouvoirs publics et accompagnées d'"un effort de convivialité d'une reconnaissance de la personne et de l’apport de fonctionnalités attrayantes" :
- Éducation dès l’école maternelle, les enfants utilisent cette technologie pour rentrer dans l’école, en sortir, déjeuner à la cantine, et les parents ou leurs représentants s’identifieront pour aller chercher les enfants.
- Introduction dans des biens de consommation, de confort ou des jeux : téléphone portable, ordinateur, voiture, domotique, jeux vidéo
- Développer les services « cardless » à la banque, au supermarché, dans les transports, pour l’accès Internet, ...La même approche ne peut pas être prise pour faire accepter les technologies de surveillance et de contrôle, il faudra probablement recourir à la persuasion et à la réglementation en démontrant l’apport de ces technologies à la sérénité des populations et en minimisant la gène occasionnée. Là encore, l’électronique et l’informatique peuvent contribuer largement à cette tâche".
Un tel "effort de convivialité" avait alors valu au GIXEL de remporter un prix Novlang aux Big Brother Awards.
GB: le ministère de l'immigration fait un autodafé des cartes d'identité
A contrario, et afin de "démontrer l'engagement du gouvernement à restaurer les libertés civiles", Damian Green, le ministre de l'immigration britannique, a de son côté officiellement enterré le projet de doter les Britanniques d'une carte d'identité :
"Il est important que le peuple aie confiance dans la façon qu'a l'État de détenir et d'utiliser des données à caractère personnel, et il est important que le gouvernement fasse confiance au bon sens et au sens des responsabilités du peuple.
Et ce n'est que le premier pas du processus que nous entamons afin de restaurer et maintenir nos libertés."
Et pour être sûr d'être bien entendu, le ministère de l'immigration a détruit, le 10 février dernier, quelques 500 disques durs et 100 bandes de sauvegarde contenant les données personnelles des 15 000 personnes ayant accepté de se porter volontaires pour être dotées de cartes d'identité, avant d'en publier les photos sur Flickr, et la vidéo sur YouTube :
Pour son tout premier discours, en mai 2010, Nick Clegg, Vice-Premier ministre libéral-démocrate du gouvernement conservateur britannique, avait en effet annoncé un "big bang" politique, visant "la liberté du plus grand nombre, et non pas le privilège de quelques-uns", afin de "rendre le pouvoir au peuple". Objectif : enterrer la société de surveillance et enrayer le "Database State" (l'État-base de données), incarné par les dérives sécuritaires du précédent gouvernement labour (de "gauche") :
"Il est scandaleux que les gens respectueux des lois soient régulièrement traitées comme si elles avaient quelque chose à cacher."
Résultat : du projet avorté de carte d'identité britannique, il ne reste plus que ça :

La Hollande, l'autre pays du contre-fichage
Le gouvernement néerlandais, lui, avait annoncé, en avril dernier, qu'il allait effacer toutes les empreintes digitales des 6 millions de détenteurs de passeports biométriques, et il vient d'annoncer qu'à compter de ce mois de juillet, les empreintes digitales ne seront plus stockées, et qu'il donnait aux responsables jusqu'à la fin août pour trouver une solution afin de détruire la base de données de 6 millions d'empreintes digitales.
Une étude avait en effet démontré le peu de fiabilité de la biométrie tel que déployée, aux Pays-Bas (par la société Morpho, celle qui, en France, a aussi emporté le marché du passeport biométrique -voir Morpho, n°1 mondial de l'empreinte digitale, troisième partie de mon enquête) : sur les 448 demandes de passeports biométriques étudiées, 55 personnes n'avaient pu faire reconnaître qu'une seule des deux empreintes de doigts qu'ils devaient entrer dans la base de donnée, et 42 personnes aucune de leurs empreintes... Autrement dit : 21% des personnes ne pouvaient pas être reconnues par leurs empreintes digitales…
Le problème ne vient pas forcément des algorithmes de Morpho, qui sont considérés comme les meilleurs pour ce qui est des empreintes digitales par l’Institut National des Standards et Technologies américain (NIST)…: nombreux sont ceux, notamment ouvriers manuels, ou personnes âgées, dont les empreintes sont trop abîmées pour être identifiables (voir aussi ces réfugiés aux doigts brûlés pour ne pas, précisément, être identifiés par leurs empreintes).
Alors que nombreux sont ceux qui craignent de voir l'arrivée de la reconnaissance faciale sur Facebook, Google et autres services et réseaux sociaux, il est tout de même étonnant qu'aucun des députés et sénateurs qui se sont à ce jour prononcés sur ce texte n'aient soulignél e risque que ce "fichier des gens honnêtes" puisse être utilisé pour identifier des gens à partir, non seulement de leurs empreintes digitales, mais également de leurs photos… Morpho est également considéré comme le n°1 de la reconnaissance de l'iris et faciale par le NIST...
jean.marc.manach (sur Facebook) @manhack (sur Twitter)
NB : comme le rappelle très opportunément Pierrick en commentaire de mon enquête sur OWNI.fr, si on vous demande de justifier de votre identité, voilà ce qu’il vous faut savoir :
La carte d’identité n’est pas un document obligatoire. L’identité peut être justifiée par un autre titre (passeport ou permis de conduire), une autre pièce (document d’état civil indiquant la filiation, livret militaire, carte d’électeur ou de sécurité sociale), voire un témoignage.
Photographie CC a2gemma
Voir aussi l'intégralité de mon enquête :
Fichons bien, fichons français !
Morpho, n° 1 mondial de l’empreinte digitale
Vers un fichage généralisé des "gens honnêtes
L’enfer, c’est les « internautres »
Le gouvernement Sarkozy veut censurer internet
auteur de "La vie privée, un problème de vieux cons ?"
Tweet
Retweet this Share on Facebook Share on Facebook
La dernière étude de Google portant sur les sites web malicieux indique que rien n'est gagné contre ces sites cherchant à infecter ou à prendre le contrôle des machines des internautes.
L'étude de Google "Trends in Circumventing Web-Malware Detection" (PDF, 12 pages) porte sur l'analyse de près de 8 millions de sites web sur une période de 4 ans et des remontées d'alertes effectuées via leur service SafeBrowsing intégré aux navigateurs Internet. Cette étude met l'accent sur les techniques utilisées par les sites malicieux pour éviter toute détection.
Le service SafeBrowsing
Le service SafeBrowsing de Google permet d'alerter un internaute dès qu'il tente de se connecter sur un site web considéré comme malicieux par Google. La base de données SafeBrowsing est alimentée par Google dès qu'un site web a été identifié comme propageant des codes malicieux. Grâce à SafeBrowsing, c'est près de 3 millions d'avertissements qui sont quotidiennement affichés aux internautes ayant fait le choix d'un navigateur utilisant compatible.
Fuir à tout prix d'être dans cette liste noire
Cette base SafeBrowsing contenant les URLs des sites malicieux, l'objectif de Google est évidemment de s'assurer qu'elle soit la plus exacte et complète possible : Si une URL est absente, l'internaute ne sera pas pas prévenu (faux négatif) ; au contraire si une URL s'y retrouve par erreur alors il sera avertit sans que cela ne soit nécessaire (faux positif).
Pour les attaquants c'est l'inverse : Ils souhaitent à tout prix que les sites web malicieux ne soient pas dans cette liste : ils vont donc user de stratagèmes divers et variés pour la détection par les outils de Google. Pour rester "sous le radar" des systèmes de Google, diverses techniques d'évasion sont utilisés.
Systèmes de Google : Des pots de miel clients
Gardons à l'esprit que les systèmes utilisés par Google pour détecter les sites web malicieux sont basés sur des machines virtuelles (VM - Virtual Machines) dans lesquelles s’exécutent des navigateurs Internet et des émulateurs de navigateurs (il s'agit de programmes "mimant" le fonctionnement d'un navigateur et donc aussi leurs failles de sécurité connues). Tout est fait pour faciliter la détection : Ni les systèmes d'exploitation (Microsoft Windows) ni le navigateur (Internet Explorer) et ses extensions ne sont pas patchés.
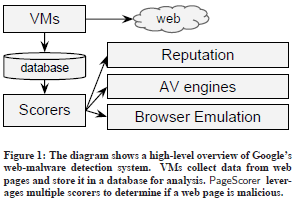
En plus de cet environnement particulièrement "propice aux attaques", tous les flux réseaux sont capturés, enregistrés et analysés par des antivirus et les évènements systèmes eux aussi sauvegardés. Pour finir, ces données sont analysées : De la sorte, une URL sera classée ou non comme étant ou non malicieuse.
Techniques d'attaques
Les techniques d'attaques ne sont guère variées : 98% d'entre elles exploitent des failles de sécurité au niveau du navigateur web, de l'une de ses extensions ou d'un plugin. Pour ce qui concerne les 2% restants les attaquent s'appuient sur l'ingénierie sociale (principalement via la demande d'installation d'un faux logiciel antivirus). La conclusion est donc que sécuriser son environnement de navigation est donc une précaution de base.
Un point intéressant sur ce 2% résiduel : Les chiffres montrent une nette explosion de ces antivirus frelatés (passage de 1 site en Janvier 2007 à 4230 sites en Septembre 2010) ; tendance à surveiller car il n'existe pas de correctif /patch pour le type de faille qu'est la naïveté, l'ignorance ou la précipitation à cliquer sur la première pop-up affichée. :-) De plus, cette technique d'attaque ne peut être détectée via des outils automatisés.
Techniques d'évasion
Pour éviter qu'un site web malicieux ne soit détecté comme tel par les systèmes de Google, les attaquants déploient des trésors d'ingéniosité. Passons en revue quelques uns d'entre-eux pour en tenter d'en ressortir quelques recommandations utiles.
- Attendre un premier clic avant de lancer le code malicieux
- Utiliser les dernières vulnérabilités
- Obscurcir le code pour contrer les émulateurs
Un premier clic avant d'attaquer
L'une des techniques pour éviter d'être détecté est de n'envoyer le code malicieux que si la page est consultée par un internaute bien réel et non pas via des outils. L'une des techniques utilisées est de n'envoyer le code malicieux qu'une fois reçu le premier clic. Google ayant identifié cette techniques ils ont fait évoluer leurs outils et c'est 40% de plus de pages qui ont pu être ainsi détectées.
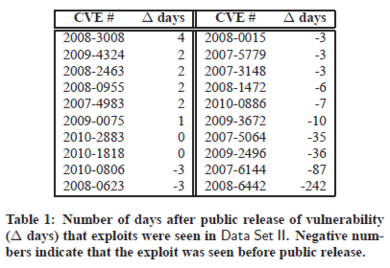
Dernières vulnérabilités et du code tordu
L'analyse de Google indique que les failles utilisées pour prendre le prendre le contrôle d'un internaute sont parmi les toutes dernières. La raison est évidente : Cela permet aux attaquants de forcer un plus grand nombre de systèmes possibles. L'effet de bord est de rendre encore plus complexe le travail de détection via les émulateurs de navigateurs car en effet ils doivent sans cesse être actualisés. Comme indiqué dans la figure suivante, l'utilisation de vulnérabilité non encore publiées publiquement n'est pas marginal.
Le code source des attaques (généralement du javascript) est lui aussi l'objet de techniques visant à le rendre difficile à analyser : L'objectif final étant que les antivirus ou IPS ne puissent détecter facilement une chaîne de caractère connue ; le chiffrement via RSA ou RC4 étant aussi couramment utilisé. Toutes ces techniques font que les codes des malwares sont complexes à émuler et donc à détecter de façon automatique.
Alors que l'utilisation de vulnérabilités "fraîches" n'a pas vocation première et directe à rendre les attaques moins visibles lors d'une analyse, les techniques d'obscurcissement le sont clairement.
Les antivirus restent peu efficaces
Le niveau de détection des antivirus est globalement assez faible, et ce malgré les efforts des éditeurs de logiciels antivirus. Cependant, une fois les codes rendus lisibles (via un passage dans les émulateurs de navigateurs Internet), la qualité de la détection par les antivirus s'améliorant de près de 40%. Les techniques d'obscurcissement de code et de chiffrement utilisés sont donc efficaces...
De plus, il est clair que les attaquants utilisent eux-mêmes les antivirus des éditeurs pour vérifier que leurs codes d'attaques ne sont pas détectés lorsqu'ils sont mis en production.
Noms de domaines multiples et blocage d'adresses IP
Pour finir, deux autres techniques sont utilisées pour éviter qu'une URL ne se retrouve dans la base SafeBrowsing. La première est de déposer un très grand nombre de noms de domaines et d'aiguiller ensuite le trafic via des points de redirection (système basé sur le principe de rotation). Les infections étant ainsi réparties sur un grand nombre de noms de domaines, celles-ci ont moins de chance de se retrouver prises dans les filets. Une autre technique apparentée à la première est de faire passer le trafic via des sites tiers (tunneling).
Enfin, une technique dite de "IP cloaking" vise simplement à servir une page totalement vierge de toute attaque dès que la requête provient des serveurs de Google SafeBrowsing. Ainsi, les serveurs de Google ne voient aucun code malicieux... simple et efficace. Sur la période de 2009-2010, cette technique a été utilisée pour environ 130.000 noms de domaines. La progression par rapport aux années précédentes indique clairement que cette technique (ou la capacité de la détecter) est en plein boom.
Quelques recommandations
L'étude de Google confirme qu'il est important de ne pas baisser la garde et que la menace posée par les infections via des sites web n'est que trop présente. Si je devais en ressortir quelques recommandations de mon couvre-chef :
- Sécuriser son environnement de navigation sur Internet (Système d'exploitation, navigateur Internet, extensions doivent impérativement être complètement à jour des correctifs). Ce n'est pas une sinécure mais c'est le point le plus important. C'est peut-être le bon moment de considérer un passage vers du desktop virtualisé.
- Un antivirus actif et mis à jour toutes les heures, voir en temps-réel. Il y a peut-être des choses à trouver du coté d'une approche "service de sécurité en mode cloud" de ce coté.
- Renforcer son programme de sensibilisation des personnes pour qu'elles restent vigilantes face aux demandes d'installation d'extensions ou de logiciels antivirus.
Bref, rien de bien nouveau me diront certains : Ils auront raison. Le hic, c'est que c'est assez rarement le cas dans beaucoup de sociétés. Celles-ci se retrouvent donc rapidement avec un nombre important de machines infectées au sein de leur réseau privé.
PS: Au risque que certains trouvent cela un peu surfait, il n'est pas nécessaire de surfer sur des sites pornos pour chopper la petite vérole numérique. Oui, ce "mythe" est encore coriace...
Et vous, avez-vous des choses à ajouter ?
Jean-François,
Photo: Graham Colm





Partez à la découverte de la biodiversité de notre planète
Depuis plusieurs années, les biologistes s'alarment face à la disparition des espèces animales et...
 « Les entreprises trouvent plus intéressant de gagner de l’argent en se faisant mutuellement des procès qu’en créant vraiment des produits. » Tel est le cinglant résumé de ce récent éditorial du Guardian qui prend appui sur l’actualité, dont le fameux rachat de Motorola par Google, pour nous livrer un constat aussi amer qu’objectif[1].
« Les entreprises trouvent plus intéressant de gagner de l’argent en se faisant mutuellement des procès qu’en créant vraiment des produits. » Tel est le cinglant résumé de ce récent éditorial du Guardian qui prend appui sur l’actualité, dont le fameux rachat de Motorola par Google, pour nous livrer un constat aussi amer qu’objectif[1].
« Les brevets étaient censés protéger l’innovation. Maintenant ils menacent de l’étouffer. » Voilà où nous en sommes clairement maintenant.
Un nouvel exemple d’un monde qui ne tourne pas rond. Un nouvel exemple où le logiciel libre pourrait aider à améliorer grandement la situation si le paradigme et les mentalités voulaient bien évoluer.
Brevets logiciels : une histoire de fous
Software patents: foolish business
Éditorial du Guardian - 21 aout 2011 (Traduction Framalang : Goofy et Pandark)
Les entreprises trouvent plus intéressant de gagner de l’argent en se faisant mutuellement des procès qu’en créant vraiment des produits.
La plupart des gens comprennent les raisons et les arguments en faveur des brevets industriels. Ces derniers fournissent à un laboratoire pharmaceutique — qui a investi une fortune dans le développement d’un nouveau médicament — une sorte d’opportunité pour, pendant une période limitée, rentabiliser sa mise initiale avant que le reste du monde ne puisse en faire des versions moins chères. Mais les brevets logiciels, bien que semblables au plan juridique, sont très différents sur le plan pratique. Quand Google a racheté la division téléphone mobile de Motorola pour 12, 5 milliards de dollars la semaine dernière, l’événement a fait des vagues dans le commerce comme dans l’industrie, parce qu’il ne s’agissait pas d’acheter les mobiles de Motorola mais son portefeuille de plus de 17000 brevets logiciels, denrée devenue la poudre d’or de l’âge numérique.
Les brevets constituent une industrie qui brasse plusieurs milliards, et les entreprises trouvent plus intéressant de gagner de l’argent en se faisant des procès qu’en créant un produit. Jusqu’au milieu des années 90 l’industrie informatique — Microsoft compris — étaient opposée à cet abus de licences. essentiellement parce que l’industrie était suffisamment innovatrice pour pouvoir se passer de la protection des brevets, qui de toutes façons incluaient des avancées technologiques relativement ordinaires, considérées comme la routine du travail d’ingénieur.
Puis, la tentation entra en scène. Les juristes des entreprises prirent conscience qu’ils pouvaient poursuivre les autres pour infraction aux brevets souvent achetés par lots. Ils furent rejoints par des entreprises « troll », constituées dans l’unique but d’acheter des brevets et de faire des procès aux autres entreprises et aux développeurs, sachant pertinemment que la plupart accepteraient une transaction à l’amiable plutôt que d’affronter les coûts prohibitifs de leur défense juridique. Les entreprise qui étaient précédemment opposées aux brevets logiciels se sont aujourd’hui lancées dans la course à l’armement. Microsoft a accumulé un gigantesque arsenal de brevets et peut taxer un fabricant comme HTC à raison de 5 dollars par téléphone portable vendu — même si le système d’exploitation Android (développé par Google) utilisé sur les téléphones HTC est « open source » et supposé disponible pour tous. Avec des centaines, si ce n’est des milliers de brevets maintenant en jeu dans un téléphone mobile, il est pratiquement impossible de ne pas enfreindre un brevet d’une manière ou d’une autre. Dans le même temps Google, confronté au puissant aspirateur à brevet de ses rivaux, a été contraint de s’acheter son propre portefeuille en réaction d’auto-défense.
Les brevets étaient censés protéger l’innovation. Maintenant ils menacent de l’étouffer. De telles acquisitions peuvent entraîner les entreprises de technologies de l’information bien loin de leur cœur de métier. Une recherche universitaire menée par le Berkman Center for Internet and Society a montré que les brevets logiciels n’ont procuré aucun bénéfice à l’industrie du logiciel, et encore moins à la société dans son ensemble. C’est dramatique, car un grand nombre d’entreprises qui étaient auparavant opposées aux brevets logiciels se sont ralliées à ce système, rendant plus difficile de trouver une solution efficace. Une fois de plus les consommateurs sont vent debout contre les entreprises. Où sont les forces régulatrices quand on en a besoin ?
Notes
[1] Crédit photo : Kalidoskopika (Creative Commons By-Sa)