 Liste de partage de Grorico
Liste de partage de Grorico










Les paramètres de confidentialité de Facebook : un pas en avant, deux pas en arrière ? Une fois de plus, le réseau social prend ses membres un peu au dépourvu... La possibilité avait été annoncée il y a quelques temps, c'est désormais chose faite : Facebook a lancé a reconnaissance faciale automatique pour les photos, est-il indiqué sur le blog officiel de la firme. Qu'est-ce que cela signifie ? Dès que vous publiez une photo sur votre profil, Facebook vous suggèrera le nom de la personne qui y apparaît, à condition qu'elle ait déjà été identifiée auparavant, sur des clichés antérieurs. Pour le moment, cette fonctionnalité n'est pas disponible dans tous les pays, mais l'implémentation est progressive ; la reconnaissance des visages devrait rapidement être possible sur votre compte.
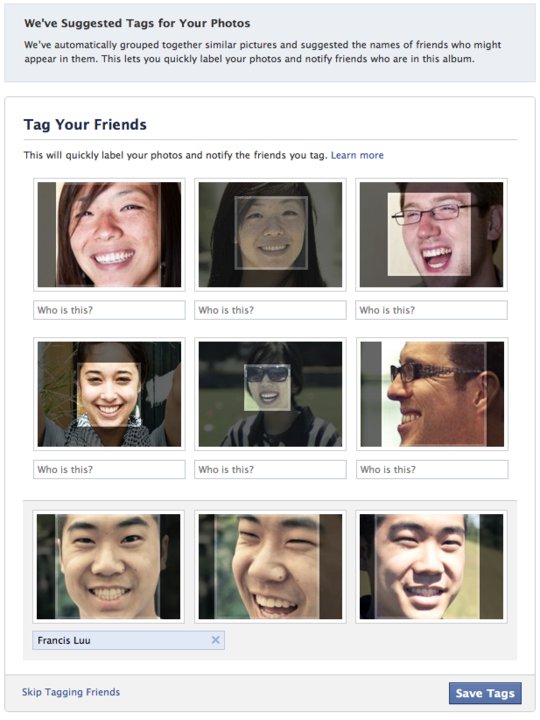
Le souci, c'est que Facebook a pour l'occasion changé automatiquement les paramètres de confidentialité par défaut. Pas très fair-play, et en contradiction avec les velléités de transparence affichées récemment. C'est-à-dire que vos paramètres ont été modifiés pour s'adapter à la reconnaissance faciale, mais pas vraiment de la bonne façon. Par défaut, vos amis peuvent donc vous identifier automatiquement sur les photos où "vous semblez apparaître". On pouvait bien entendu être taggué manuellement sur les photos, mais la systématisation du procédé risque de donner lieu à des quiproquos bizarres, et peut-être à des taggages massifs. On imagine les dégâts qui peuvent être causés par cette nouveauté, conçue à la base pour faciliter la vie des utilisateurs.
Pour désactiver ce paramètre, rendez vous Compte > Paramètres de confidentialité > Personnaliser les paramètres, puis, dans la rubrique "Ce que d'autres partagent", cliquez sur "Modifier les paramètres" à la ligne "Suggérer à mes amis les photos où j’apparais", vous verrez ainsi apparaître cette boîte de dialogue :
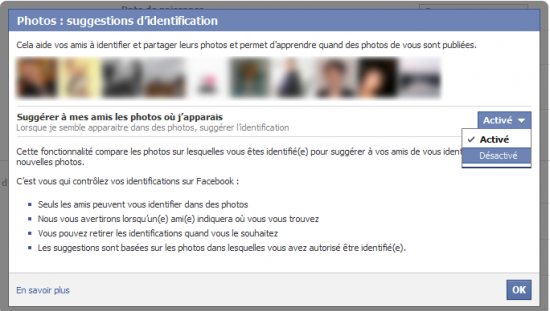
Et cliquez donc sur "Désactivé" pour finir. Au-delà de la petite innovation sympathique, on peut vraiment déplorer le fait que Facebook ne prévienne pas vraiment les utilisateurs de ses changements de paramètres de confidentialité par défaut - et ce n'est pas tout à fait la première fois que cela arrive. Dommage !
Source : Mashable
Il y a encore quelques années, la mention du langage Javascript faisait se hérisser les cheveux de la plupart des programmeurs. Beaucoup le considéraient alors comme un boulet hérité des années Netscape dont on se serait volontiers passé s'il y avait eu une alternative viable. Grâce à l'évolution technologique récente, l'explosion et la démocratisation des RIA (Rich Internet Applications) et la libéralisation du marché des navigateurs (montée en puissance de Firefox et Google Chrome notamment), le Javascript est devenu un citoyen de première classe du paysage web.
Alors Javascript en tant que langage permettant de développer un serveur d'application, pourquoi pas ?
Car malgré ses défauts mille fois pointés du doigt, Javascript est un langage possédant une expressivité impressionnante, orienté objet, doté de principes hérités des langages fonctionnels (Lisp, etc.) comme la closure ou les lambda-functions, et intégrant le paradigme de programmation évènementielle... Bien loin, en fait, du langage jouet que certains décrivent encore !
Cet article a pour vocation de présenter node.js, une technologie basée sur V8, le moteur javascript de Google Chrome, dont elle étend les capacités en ajoutant de nombreuses fonctionnalités d'I/O (Entrées/Sorties). Suite à quelques généralités à son sujet, nous mettrons les mains dans le code et ferons l'ébauche d'un serveur basique capable de répondre à des requêtes HTTP. Nous conclurons par une ouverture sur quelques frameworks et bibliothèques associées à node.
Présentation et historique
Node.js est un projet né au cours de l'année 2009 (les premières traces du projet remontent à février 2009, la première « release » (0.0.1) à mai 2009). C'est un projet open-source, sous licence MIT. Les sources sont disponibles sur github, ainsi qu'une partie de la documentation, notamment concernant l'installation de node sur votre environnement. L'API, quant à elle, se trouve sur nodejs.org.
C'est un projet actif et dynamique qui bénéficie d'une release mineure toutes les deux semaines environ. Fin avril 2011, la dernière release stable est la version 0.4.7. Le créateur et principal mainteneur est Ryan Dahl.
Le principe fondateur de cette technologie est d'offrir une surcouche au moteur V8 permettant de gérer les entrées/sorties de manière évènementielle. Ces fonctionnalités sont fortement orientées vers les applications réseau (support de HTTP, HTTPS, TCP, ...). La gestion évènementielle élimine les appels bloquants de l'application, ce qui permet une meilleure concurrence par rapport aux systèmes traditionnels basés sur l'utilisation de threads, ainsi qu'une empreinte mémoire fortement diminuée, comme le prouvent de nombreux benchmarks. En somme, node.js pourrait devenir, une fois arrivé à maturité, la référence en termes de développement d'applications web à fort trafic.
Réalisation d'un serveur basique en node.js
Nous allons à présent tenter de donner un aperçu de ce qu'est la programmation avec node.js. Notre objectif est de réaliser un petit serveur http très simple capable de servir les fichiers HTML contenus dans un dossier donné. Nous considèrerons que vous avez une connaissance basique du protocole HTTP et du langage Javascript.
En guise d'avant-propos, il faut signaler que node.js fonctionne particulièrement bien sur des systèmes UNIX (Linux, MacOS, BSD...), mais que l'utilisation sous Windows est (à l'heure actuelle) complexe et requiert des outils intermédiaires comme Cygwin ou MinGW. Ici, nous considèrerons que vous avez accès à un système UNIX avec une version récente de Python installée (Python est nécessaire pour l'installation de Node mais n'est pas utilisé au runtime).
Téléchargez la dernière version de node sur nodejs.org, décompressez l'archive, allez à la racine du dossier extrait et exécutez les commandes suivantes :
mkdir ~/local ./configure --prefix=$HOME/local/node make make install export PATH=$HOME/local/node/bin:$PATH
Une fois cela fait, si tout s'est bien passé, vous devriez pouvoir exécuter la commande node -version et obtenir un affichage du type :
$ node --version
v0.4.7
$Maintenant que node est installé, il est temps de commencer à coder. On peut commencer par écrire un serveur HTTP en quelques lignes qui répondra « Hello World » dès qu'on le requêtera. Pour cela on crée un fichier (par exemple « node-example.js ») contenant le code suivant :
// On utilise le module http grâce à l’instruction require, qui récupère // un objet javascript doté de diverses fonctions utiles que nous stockons // dans notre variable http var http = require('http'); var server = http.createServer( // on crée l’objet server. // on définit une fonction lambda qui se chargera de répondre lorsqu'un // client émettra une requête sur notre serveur. function(request, response) { // la réponse http sera formée d’un header indiquant le statut 200 // (requête traitée avec succès) response.writeHead(200); // On inscrit ‘Hello World!’ suivi d’un retour à la ligne dans le corps // de la réponse. response.write('Hello World !\n'); response.end(); // On indique la fin de la réponse. }); server.listen(8000); // On dit au serveur d’écouter sur le port 8000.
Sauvegardez le fichier, puis lancez la commande node node-example.js. À partir de là, vous devriez pouvoir accéder au serveur par exemple depuis votre navigateur via l'adresse http://localhost:8000/. Jusqu'ici, notre code est d'une extraordinaire simplicité. Maintenant, créons un fichier index.html avec quelques balises, que notre serveur répondra.
var http = require('http'); // le module "filesystem" qui va nous permettre de lire un fichier var fs = require('fs'); function readFileData(callback) { // on déclare une fonction readFileData fs.readFile('index.html', // on demande la lecture du fichier index.html // on exécute la fonction de callback une fois que le fichier a été lu. // C'est dans cette fonction qu'on manipulera les données récupérées. callback ); } var server = http.createServer( function(request, response) { // On définit la fonction de callback de la lecture du fichier. // Le premier paramètre contiendra l'éventuelle erreur lors de // la lecture, le second les données lues. function respond(err, data) { // Grâce à la closure, on a accès à response à l'intérieur de // cette fonction "nestée". if (err) { // si on a rencontré une erreur response.writeHead(500); // "Internal server error" response.end(); } else { // sinon, on peut répondre avec les données. response.writeHead(200, // un objet js contenant des headers http. // Ici, on définit le content-type. { 'Content-Type' : 'text/html' } ); response.write(data); response.end(); } } // on appelle readFileData en lui passant notre fonction callback. readFileData(respond); }); server.listen(8000);
Redémarrez le serveur (node node-example.js après avoir interrompu le processus précédent), vous pourrez alors visualiser votre fichier index.html depuis votre navigateur. Si le fichier n'existe pas, le serveur vous renverra une erreur HTTP 500. On notera que pendant la lecture du fichier, le serveur en lui-même n'est pas bloqué et peut traiter d'autres requêtes !
A présent, nous voulons pouvoir servir différents fichiers HTML en fonction de l'URL. Reprenons donc notre exemple et améliorons-le.
var http = require('http'); var fs = require('fs'); // On utilise le module url pour parser l'URL de la requête. var url = require('url'); // On ajoute un paramètre 'file' qui indique à quel fichier on veut accéder. function readFileData(file, callback) { fs.readFile(file, callback); } var server = http.createServer( function(request, response) { var parsedUrl = url.parse(request.url); // on parse l'URL de requête // le pathname contient le chemin du fichier demandé. var requestedFile = './' + parsedUrl.pathname; function respond(err, data) { if (err) { response.writeHead(500); } else { response.writeHead(200, { 'Content-Type' : 'text/html' }); response.write(data); } response.end(); } // On indique quel fichier on doit lire. readFileData(requestedFile, respond); }); server.listen(8000);
Nous avons très peu de choses à ajouter pour que cela fonctionne. Attention néanmoins, ce code n'empêche pas l'accès à des fichiers contenus dans des dossiers parents. On pourrait aussi faire en sorte de retourner une erreur 404 lorsque le fichier n'existe pas au lieu de l'erreur 500 que nous choisissons par défaut pour n'importe quelle erreur de lecture. Idéalement, il faudrait aussi ajouter un cache capable de stocker le contenu des fichiers plutôt que de le relire à chaque fois, et afficher le fichier index.html par défaut si aucun fichier n'est indiqué dans le pathname.
var http = require('http'); var fs = require('fs'); var url = require('url'); var buffer = {}; function readFileData(file, callback) { if (buffer[file]) { // si le buffer connaît le fichier, on appelle directement le // callback avec le contenu du buffer. callback(null, buffer[file]); } else { fs.readFile(file, function(err, data) { if (!err) { // si l'on a pas rencontré d'erreur, on crée une entrée // dans le buffer avec les données lues. buffer[file] = data; } callback(err, data); }); } } function checkPathName(path) { var regex = /(\.\.$)|(\.\.\/)/; return !regex.test(path); } var server = http.createServer( function(request, response) { var parsedUrl = url.parse(request.url); var requestedFile = './' + parsedUrl.pathname; if (!checkPathName(requestedFile)) { // Si le pathaname contient '..', on refuse de servir le fichier // avec une erreur 403. response.writeHead(403); response.end(); return; } else if (requestedFile == './' || requestedFile == './/') { requestedFile = './index.html'; } function respond(err, data) { if (err) { if (err.code == 'ENOENT') { // Le fichier n'existe pas. response.writeHead(404); response.write('Sorry, this file is not available.'); } else { response.writeHead(500); } } else { response.writeHead(200, { 'Content-Type' : 'text/html' }); response.write(data); } response.end(); } readFileData(requestedFile, respond); }); server.listen(8000);
Nous avons à présent un serveur HTTP basique capable de servir des fichiers HTML, en seulement quelques lignes de code. En partant de là on peut apporter un grand nombre d'autres fonctionnalités.
Le microcosme node.js
Node.js a pour vocation de rester relativement bas-niveau, offrant ainsi les briques de base pour construire une application réseau hautement performante. Mais la communauté qui s'est formée autour de node apporte énormément d'outils pour rendre le développement d'applications simple, intuitif et viable pour des projets d'entreprise.
Npm
NPM est l'abréviation de Node Package Manager. C'est en quelque sorte l'équivalent de ce que pourrait être aptitude ou apt-get (les gestionnaires de paquets sous Debian et Ubuntu), et l'interface est très similaire. Pour télécharger la dernière version d'express, par exemple, il suffit d'exécuter la commande npm install express et de laisser l'utilitaire faire son travail. Si quelques mois plus tard, on désire obtenir la dernière version d'express, on exécutera simplement npm update express.
Cet utilitaire, ainsi que des informations quant à son installation et son utilisation sont disponibles sur github, comme la grande majorité de l'écosystème node.
Express
Plus haut, nous avions commencé à écrire notre serveur HTTP capable de servir des fichiers statiques. Bien que l'exemple soit utile à la compréhension de la mécanique de node, ce n'est pas une solution viable pour le développement d'une « vraie » application web. Fort heureusement, Express existe. Il s'agit d'un framework web basé sur node.js - sans doute le plus abouti d'entre eux - et Ryan Dahl lui-même le suggère à de nombreuses reprises sur le site de node ou lors des conférences qu'il donne. Le framework se base sur le design-pattern MVC (Model View Controller) et inclut entre autres le support du routage, intègre plusieurs langages de template pour les vues (notamment Jade), supporte les vues partielles, etc.
En d'autres termes, Express est sans doute, à l'heure actuelle, le point de départ de toute application web basée sur node.
Wordsquared.com
Ce dernier point s'adressera particulièrement aux sceptiques, pour lesquels node n'est encore qu'un gadget. Le site wordsquared.com est l'un des quelques sites basés sur node aujourd'hui. Wordsquared est particulier, car il s'agit d'une démonstration technologique et technique d'une rare qualité : il s'agit en fait d'un jeu de scrabble géant, multijoueur, en temps réel. La réalisation de l'application est impressionnante, tout comme sa réactivité. C'est sans aucun doute la meilleure preuve de maturité du combo node.js/express.
... Et les autres !
Bien entendu, ce ne sont là que quelques-uns des éléments qui composent le microcosme node.js, et l'on trouve de nombreux modules (allant du parser XML au client MySQL) ainsi que de nombreuses applications construites sur node.
Cette technologie éveille les curiosités et fait buzzer le web, et non sans raison : une fois que le pas de la maturité sera franchi, node pourrait être une alternative sérieuse à des solutions comme Ruby On Rails ou django. Avec son modèle évènementiel et la possibilité d'écrire toute la pile client-serveur en un seul langage (javascript !), il ne fait aucun doute que node fera partie du web de demain.
Emission
Titre : on prolonge l'émission avec l'INRIA.
Description : .
Episode
Titre : L'apprentissage des robots avec Pierre-Yves Oudeyer.
Description : Difficile d'imaginer des robots capables d'apprendre de nouveaux savoir-faire comme le feraient des bébés... Pourtant, Pierre-Yves Oudeyer, chercheur en robotique comportementale et sociale, le conçoit. Il va nous expliquer les tenants et les aboutissants de cette idée au micro de Xavier de La Porte. Source : http://interstices.info/jcms/c_43512/a-propos-de-lapprentissage-des-robots.
Début : 25 mai 2011 10:00:01.
Durée : 01:33:22.
« Un jour nous regarderons le XXe siècle et nous nous demanderons pourquoi nous possédions autant de choses » affirmait récemment Bryan Walsh dans TIME Magazine qui consacrait la Consommation Collaborative comme l’une des dix idées amenées à changer le monde. L’économie du partage se propage : du transport aux voyages en passant par l’alimentation, le financement de projets et la distribution, tous les secteurs ou presque sont investis par cette nouvelle économie. Pourquoi acheter et posséder alors que l’on peut partager semblent dire des millions d’individus. Les statistiques sont éloquentes, nous explique Danielle Sacks dans l’un des articles les plus complets sur l’émergence de l’économie du partage : « Alors que plus de 3 millions de personnes dans 235 pays ont déjà « couchsurfé », ce sont plus de 2,2 millions de trajets en vélo libre-service (tels que le Velib’ à Paris) qui sont effectués chaque mois dans le monde. »


Article initialement publié sur OWNI.eu.
Nul doute que les monnaies cryptées vont continuer à se développer. Les nouveaux usages qu’elles permettent emportent haut la main la lutte contre les banques dont nous avons hérité les systèmes de transaction sur rendez-vous, au cas par cas. Quid des jours fériés ? Quid des avoirs gelés ? Des frais bancaires ? Tout ces concepts sont devenus obsolètes et non-pertinents.
Il se peut que Bitcoin ne devienne pas le standard ultime des monnaies chiffrées, mais ce n’est pas important. C’est comme pour le partage de fichiers : peu importe que les gens utilisent Bitorrent, OneSwarm ou un autre logiciel plus performant encore. C’est le concept de partage de fichiers qui est intéressant, pas le logiciel.
Il y a une certaine extase au moment de transférer quelques centimes de bitcoins à quelqu’un situé à l’autre bout de la planète. Le fait qu’il reçoive cet argent instantanément, sans intermédiaire, et sans personne pour s’y opposer (à moins qu’elle vienne s’en prendre physiquement à moi), est assez enthousiasmant. Cette sensation est profonde. Tout comme les ramifications. Mais dans cet article, je voudrais me concentrer sur les implications politiques des monnaies chiffrées.
Pour l’instant, les cas d’usage des monnaies chiffrées sont limités par l’effet de réseau. Vous ne pouvez pas vraiment utiliser bitcoin pour des choses concrètes. Mais d’un point de vue politique, le développement de ces monnaies signifie que les systèmes de sécurité sociale et de taxation doivent être repensés et réformés aussi rapidement que profondément.

Repenser la fiscalité dans un monde de monnaies virtuelles chiffrées
Avec les monnaies chiffrées, le gouvernement ne peut pas inspecter la richesse des individus, ni leurs revenus ou leurs dépenses. Et ce y compris en faisant usage de la force. Je connais beaucoup de gens dans le gouvernement qui – victimes classiques du biais de la normalité – vont se dire : “mais nous devons pouvoir le faire !”. Mais peu importe, vous ne pourrez pas. Point barre.
Autrement dit, ni le système fiscal, ni la protection sociale ne peuvent être conditionnés au revenu ou à la fortune. Même si seulement 5% de la population utilise des monnaies cryptées, la morale fiscale implique de s’assurer que tout le monde ait le sentiment de payer de manière juste et que les fraudeurs courent un risque crédible d’être puni. Avec les monnaies chiffrées, le contrat social se retrouve brisé.
Et comme nous y arriverons inéluctablement d’ici une décennie, ce n’est pas le moment de faire l’autruche.
Commençons par le problème fiscal. L’imposition ne pourra plus être basée sur un revenu ou sur le patrimoine : de l’impôt sur le revenu aux taxes patronales et salariales, ces ressources passeront par la fenêtre – remarquez, le coté positif, c’est que par définition, le travail illégal cessera d’exister.
Que reste-il donc à taxer ? Nous pouvons imposer le foncier comme nous le faisions au XIXème siècle. Mais bon, ça ferait justement un peu trop XIXème siècle, non ? Alors quoi d’autre ? Nous pouvons taxer les immeubles, les maisons, les voitures, l’essence…. et toutes ces taxes si impopulaires. Très bien, mais nous pouvons aussi taxer la consommation.
La taxe sur la valeur ajoutée (TVA) est déjà l’une des premières ressources fiscales des gouvernements européens. C’est un système différent d’une simple taxe à la vente dans le sens où elle est appliquée à chaque étape de la chaîne de production jusqu’à la vente finale. En admettant que nous ayons une TVA à 25%, le fabricant d’origine ajoute cette taxe à son prix global. Puis le revendeur se fait rembourser sa TVA auprès du gouvernement, mais ajoute à nouveau 25% à ses prix. Ce système crée un effet positif car cela incite chaque maillon de la chaîne à déclarer les taxes qu’il perçoit, puisqu’il peut ainsi se faire rembourser la TVA précédemment payée.
Si l’on regarde les chiffres de la Finlande et de la France, on se rend compte qu’en doublant le taux de TVA, on pourrait abolir tous les autres impôts sur la personne. La pression fiscale resterait la même, tout comme les revenus de l’État. En fait, seule l’assiette fiscale changerait : on taxerait la consommation plutôt que le revenu, mais ces deux variables sont de toute façon très corrélées en théorie.
Ce système comporte deux autres avantages. Le premier est évidemment l’abandon de l’impôt sur les personnes physiques. Plus aucun citoyen n’aurait de comptes à rendre à une quelconque autorité fiscale. Plus jamais. Seules les entreprises seraient concernées, en tant que collecteurs d’impôt (même si au final, c’est bien les ménages qui sont taxés via leur consommation).
Le second avantage, c’est que l’infrastructure et la bureaucratie sont déjà en place. Il suffirait simplement d’ajuster un pourcentage. Une fois cela fait, un bon paquet de fonctionnaires (ceux qui s’occupent de l’administration des autres taxes) pourront juste arrêter leur travail.
Mais bien sûr, il y a aussi des inconvénients. Le premier est que l’imposition serait parfaitement plate. Cela toucherait donc plus durement les moins fortunés, ce que nous voulons éviter. La taxation progressive est généralement perçue comme un aspect juste et équitable d’une société viable.
Afin de rétablir la progressivité de l’imposition, le moyen le plus normal serait d’instaurer une réduction d’imposition. Mais cela est difficilement applicable avec la TVA : il faudrait un système de traçabilité des dépenses, permettant à chacun de prouver qu’il n’a pas dépassé son quota de crédit de TVA… Je vous laisse imaginer la tête de votre kiosquier quand vous achèterez votre journal à 1,2€.
Bref, il faut tourner le problème dans un autre sens.

Repenser l’état providence
Les systèmes de protection sociale ont toujours été basés sur un manque de revenu, de richesse, ou des deux. Mais si on ne peut plus les mesurer, que fait-on ?
Je ne vois que deux options : soit vous donnez à personne, soit vous donnez à tout le monde. Or, comme donner à personne n’est pas vraiment une option, il ne nous reste que la possibilité de donner à tous, sans aucune condition. C’est le scénario du revenu de base inconditionnel, le salaire citoyen.
Ce système ferait d’une pierre deux coups, puisque la combinaison de la taxation unique sur les dépenses et le revenu de base universel équivaut en fait à une réduction d’impôt de base. En effet, jusqu’à ce que le montant de TVA payée atteigne le revenu de base perçu, c’est comme si vous n’aviez rien payé. Et en plus, vous avez un revenu minimum de subsistance. Ce que nous avons déjà, d’une certaine façon.
Ce système aurait aussi pour effet positif de supprimer la nécessité d’autres systèmes de protection sociale, des allocations chômage aux prêts étudiants, et toute la bureaucratie qui va avec.
Certaines personnes prétendent que ce salaire citoyen tuerait toute motivation à travailler. J’ai déjà répondu à ces objections. En version courte : GNU/Linux et Wikipédia.
La fin de l’imposition des revenus
Les monnaies chiffrées arrivent de toute façon. Qu’il s’agisse de bitcoin ou d’autre chose, ou même d’un nouveau protocole d’échange qui utilise plusieurs monnaies différentes. Ce qui est important de comprendre, c’est qu’en moins d’une décennie, nous aurons perdu notre capacité à capter la richesse et les revenus des citoyens.
Cela signifie alors qu’il ne peut y avoir de système fiscal basé sur l’imposition des richesses ou des revenus.
Je pense que le moyen le plus approprié de faire face à ce problème, est de déplacer l’assiette d’imposition sur la consommation et ainsi transvaser l’imposition sur le revenu vers la TVA. Pour conserver la progressivité de l’imposition, ainsi que pour conserver une protection sociale fonctionnelle, nous aurons aussi besoin de combiner ce système avec un revenu de base inconditionnel accordé à chaque citoyen, afin de garantir une certaine subsistance.
Article initialement publié sur le site de Rick Flakvinge.
Traduction : Stanislas Jourdan
Illustrations CC FlickR: matthileo, Ivan Walsh, Muffet