 Liste de partage de Grorico
Liste de partage de Grorico
"L’idée fondatrice d’OpenMesh est que nous puissions utiliser de nouvelles techniques pour créer un réseau Internet secondaire dans les pays comme la Libye, la Syrie, l’Iran, la Corée du Nord et d’autres régimes répressifs dans lesquels les citoyens ne peuvent pas communiquer librement. En créant des routeurs mobiles qui se connectent entre eux, nous pourrions créer un réseau auquel les téléphones portables et les ordinateurs personnels se connecteraient. La première priorité serait de relier les personnes entre elles, la seconde de les relier au reste du monde. Sur un second front, nous pourrions utiliser des connexions intermittentes par satellite afin que les citoyens de ces pays puissent mettre en ligne et télécharger des informations avec le reste du monde. OpenMesh se veut un lieu d’échange d’informations pour connecter les meilleures idées existantes et mettre les outils entre les mains de tous." Shervin Pishevar - http://openmeshproject.org
L’arrivée de l’HTML5 et de ses très nombreuses fonctionnalités va causer un grand bouleversements dans le développement de sites web et d’applications riches. Cette technologie apporte son lot de nouveautés sur la sémantique HTML, avec de nombreuses nouvelles balises, et se synchronise avec la démocratisation du CSS3. Elle bouscule également le support multimédia sur le web, actuellement dominé par le Flash, en permettant aux développeurs d’insérer des contenus multimédias nativement utilisables par le navigateur.
Cet article va quant à lui aborder un tout autre thème que sont les nombreuses nouvelles fonctionnalités “non-multimédia” telles que les websockets, la géolocalisation ou le stockage de données côté client. L’API Javascript s’est en effet énormément enrichie avec l’HTML5, et nous allons voir ensemble ces nouveautés avec quelques exemples.
LocalStorage (stockage de données côté client)
Le LocalStorage permet de stocker des informations dans le navigateur de l’utilisateur. Ces informations sont extrêmement faciles à manipuler, et contrairement aux cookies, elles ne sont jamais envoyées au serveur. Il est également important de noter que chaque navigateur a son propre espace de stockage. Par conséquent, sauvegarder une information dans Firefox ne permettra pas de l’utiliser sous Chrome par exemple.
Une telle fonctionnalité peut par exemple s’utiliser dans le cadre d’une application hors-ligne, telle qu’une page web servant de “Liste des tâches” ou tout simplement pour sauvegarder un identifiant de connexion.
Son utilisation est on ne peut plus simple.
Sauvegarder une valeur dans le navigateur se fait via la fonction setItem :
window.localStorage.setItem("Nom", "Valeur");
Récupérer une valeur se fait via la fonction getItem :
window.localStorage.getItem("Nom");
Base de données SQL locale
Lorsque vous développez une application web, et que vous souhaitez stocker des données en grande quantité, et les organiser correctement, vous pouvez utiliser la nouvelle base de données SQL locale plutôt que le LocalStorage qui est assez limité.
Voici comment exécuter une requête SQL locale en Javascript :
var db = window.openDatabase("Nom", "Version"); db.transaction(function(tx) { tx.executeSql("SELECT * FROM Table", [], successCallback, errorCallback); });
On peut notamment voir par cet exemple qu’il contient une ouverture de connexion à la base de données, la requête sous forme de string au format SQL standard, ainsi qu’une fonction de CallBack, qui sera appelée avec le résultat de la requête SQL qui pourrait par exemple être la fonction suivante :
function successCallback(transaction, results) { var message = ""; for (var i=0; i<results.rows.length; i++) { var row = results.rows.item(i); message += row["name"] + ","; } alert(message); }
Cette fonction affiche une suite de noms récupérés dans la base SQL, grâce à l’objet "results" automatiquement généré lors de l’exécution de la requête SQL.
Applications Web Offline
Une application web offline au sens de l’HTML5 offre une grande flexibilité au moment du changement Online - Offline. C’est une notion particulièrement importante du fait que nous sommes dans l’ère de l’avènement de la téléphonie smartphone, lesquels peuvent voir leur connexion fréquemment coupée.
La plupart des applications de gestion d'e-mails ou de messagerie instantanée possèdent des fonctionnalités comme “l’envoi lorsque la connexion sera récupérée”, et c’est exactement ce qui nous intéresse dans les applications web offline en HTML5.
L’essentiel de cette technique passe par la mise en cache de fichiers, qui se déclare dans un fichier MANIFEST.
Il se déclare en attribut de la balise html comme ceci :
<!DOCTYPE HTML> <html manifest="test.manifest">
Dans ce fichier MANIFEST on liste les éléments à mettre en cache :
CACHE MANIFEST index.html style/default.css images/logo.png images/backgound.png
D’autres sections peuvent être ajoutées comme par exemple les fichiers à ne pas mettre en cache, ou encore des fichiers alternatifs au cas où les premiers ne soient pas atteignables.
L’API Javascript fournit un objet ApplicationCache qui permet de mettre à jour le cache très simplement :
window.applicationCache.update();
Ou encore d’invalider le précédent cache lorsque le nouveau est prêt :
window.applicationCache.swapCache();
L'objet window est maintenant doté d'une propriété booléenne online, accompagnée des évènements online et offline, afin d’adapter le traitement Javascript et utiliser par exemple le stockage local en attendant de retrouver la connexion.
La géolocalisation
Cette nouveauté apportée par l’HTML5 est l'une des plus attendues. Il était déjà possible de tracer une IP pour savoir à peu près où était situé l’utilisateur. C’est maintenant beaucoup plus simple grâce à l’intégration native de la géolocalisation dans le navigateur et dans l’API Javascript.
L’API permet de très nombreuses choses comme le suivi de la position dans le temps ou encore le calcul de la vitesse. Pour cet exemple, nous nous intéresserons uniquement à l’obtention des coordonnées de l’utilisateur en Javascript.
La récupération des données de géolocalisation fonctionne également par CallBack, comme montré ci-dessous :
navigator.geolocation.getCurrentPosition(showPosition, onError); function showPosition(position) { var lat = position.coords.latitude; var lng = position.coords.longitude; // Traitement }
La fonction getCurrentPosition prend en paramètre deux fonctions. Elle va injecter en paramètres de la première les coordonnées récupérées afin qu’elles soient traitées. Cet exemple montre à quel point il est facile d’utiliser la géolocalisation et les nombreuses possibilités qu’elle offre en très peu de lignes de code. Ceux qui souhaitent aller un peu plus loin pourront suivre un tutoriel de géolocalisation en HTML5 et exploiter les coordonnées grâce à l'API Google Maps.
Web Forms Avancés
La vérification des données de formulaire envoyées par un client est une préoccupation présente dans 100% des projets web. Que ce soit côté client en Javascript ou côté serveur, il est extrêmement important de s’assurer de la validité de ces informations. Les formulaires avancés HTML5 sont là pour ajouter une couche de sécurité dans les informations envoyées par les clients.
En pratique, il suffit d’ajouter un attribut aux balises input des formulaires afin d’en spécifier le typage. Ensuite, le CSS se charge de la mise en forme avec le pseudo-format :invalid.
<!-- :invalid { background-color: red; } --> <input type="range" value="0" /> <input type="search" /> <input type="text" /> <input type="color" value="blue" /> <input type="number" value="123" /> <input type="email" value="some@email.com" /> <input type="tel" value="1234" />
De très nombreux attributs existent, comme l’illustre cet exemple.
Une liste plus complète se trouve sur le site du W3C.
Il est cependant important de noter que pour le moment, seul le navigateur Opera les implémente totalement.
Le Drag and Drop
Il est déjà possible d’effectuer des Drag and Drop en Javascript en utilisant des bibliothèques Javascript (jQuery UI par exemple). HTML5 veut rendre le “Glisser-déposer” natif aux navigateurs. Pour ce faire, il faut d’abord comprendre le fonctionnement du Drag And Drop. En HTML5, le but n’est pas de déplacer visuellement des éléments sur l’écran, mais d’avoir une réelle interactivité avec les éléments HTML.
Pour illustrer ceci avec un exemple nous avons besoin d’un élément à déplacer("dragMe", ainsi qu’une zone dans laquelle déposer l’élément ("dropHelloHere").
L’élément est rendu "draggable" comme ceci :
<h1 id="dragMe" draggable="true" ondragstart="drag(this, event)">Hello</h1>
Ensuite, on crée la zone de destination :
<div id="putHelloHere" ondrop="drop(this, event)" ondragenter="return false" ondragover="return false"></div>
Enfin, on a besoin d’un peu de Javascript pour lier le déplacement aux actions :
function drag(target, e) { e.dataTransfer.setData("Test", target.id); } function drop(target, e) { var id = e.dataTransfer.getData("Test"); // Traitement }
Un évènement est déclenché au début du drag, qui stocke l’id de l’élément en cours de drag. Une fois l’élément “droppé”, la fonction drop() récupère l’id en question et peut effectuer un traitement sur celui-ci.
On notera que des évènements peuvent également être placés lors du survol de la souris (ou du doigt) de la zone dans laquelle on veut déposer l’élément.
Les Web Workers
Les Web Workers ont pour mission d’exécuter des traitements lourds et gourmands en ressources processeur. Habituellement, lorsque du code Javascript effectue d’importants traitements, le navigateur est paralysé (comme dans le cas d’un bug avec une boucle infinie).
Un navigateur est donc totalement monotâche et il fallait ruser avec des timers pour ne pas faire crasher le traitement.
Avec les Web Workers, on peut placer un traitement en tâche de fond et communiquer avec lui pendant qu’il est exécuté.
Voici un exemple concret d’utilisation :
appel-worker.js
var worker = new Worker('worker.js'); worker.onmessage = function(event) { alert(event.data); };
On crée un worker (qui est toujours situé dans un fichier séparé), puis on lui lie une fonction “onmessage” qui va afficher un popup avec la réponse du worker.
worker.js
self.onmessage = function(event) { // Traitement self.postMessage("Réponse"); }
Un Worker communique toujours par envoi de String. Ici il exécute un traitement puis renvoie “Réponse” dès qu’il a terminé.
Les Websockets
Elles sont l’une des nouvelles fonctionnalités HTML5 les plus puissantes. La communication entre un client et un serveur s’effectue toujours lorsque le client le demande, elle est mono-directionnelle. L’arrivée de l’AJAX n’a fait que contourner cette faiblesse en envoyant des requêtes régulièrement afin d’actualiser l’information affichée à l’utilisateur. L’arrivée des Web Sockets révolutionne cette communication en autorisant le navigateur du client à réagir lorsque le serveur demande à interagir avec lui.
Encore une fois, l’utilisation de cette fonctionnalité HTML5 se veut extrêmement simple.
Tout d’abord on initialise la connexion au serveur de socket :
var socket = new WebSocket("ws://test.example.com");
Ensuite on peut envoyer un message au serveur de socket afin de lui confirmer la connexion :
socket.onopen = function(event) { socket.postMessage("Hello, WebSocket"); }
Puis on peut faire réagir le navigateur lorsque l’on reçoit une réponse du serveur :
socket.onmessage = function(event) { alert(event.data); }
Enfin, on affiche un message lorsque la connexion est fermée :
socket.onclose = function(event) { alert("closed"); }
On obtient ainsi une interactivité avec le serveur parfaitement synchronisée, contrairement aux méthodes AJAX qui ont toujours un temps de latence, qui sert à ne pas surcharger le serveur d’appels de vérifications.
Conclusion
L’HTML5 devient de plus en plus concret et les navigateurs s’attèlent à intégrer le plus de fonctionnalités possibles. Pour le moment Chrome, Opera et Safari sont les plus avancés dans le domaine. Firefox sort très bientôt en version 4, ainsi qu’Internet Explorer 9, qui sont de loin les navigateurs les plus utilisés, et qui vont réellement être le coup d’envoi de l’HTML5.
En attendant il est bien entendu possible de se familiariser avec toutes ces fonctionnalités en les testant sur les navigateurs compatibles.
Pour terminer, voici un template extrêmement complet de site HTML5, il s’agit d’un projet de qualité réalisé par un ingénieur Google, grand acteur de l’HTML5. C’est un excellent point de départ pour tout développeur qui souhaite se plonger dans un site nouvelle génération.
 Il fut un temps où de nombreux architectes réseaux et systèmes s'arrachaient les cheveux pour optimiser au mieux leur infrastructure d'hébergement web.
Il fut un temps où de nombreux architectes réseaux et systèmes s'arrachaient les cheveux pour optimiser au mieux leur infrastructure d'hébergement web.
La raison principale ? Offrir une qualité de service à la hauteur de la volumétrie des données distribuées aux visiteurs de leur(s) sites(s) web.
Puis vinrent sur le marché des solutions de Content Delivery Network, abrégées sous l'acronyme CDN, offrant à ces mêmes architectes un réseau de serveurs capables de distribuer les données via l'utilisation de mécanisme de cache.
Principes du serveur web
Un serveur web est constitué d'un ensemble de processus systèmes dont le rôle consiste à accomplir les principales tâches fonctionnelles suivantes :
- être à l'écoute des requêtes HTTP sur un port défini (généralement le port 80)
- répondre par l'envoi du contenu du fichier demandé (ex: un fichier image, un fichier PDF, ...)
- répondre par l'envoi du résultat d'un script exécuté (ex: un script PHP, un script Python, ...)
- stocker dans un fichier log le détail des informations demandées et échangées
Afin d'optimiser la capacité du serveur à répondre à plusieurs demandes simultanées, le processus maitre distribue les tâches à effectuer à un certain nombre de processus fils.
Néanmoins, tout système d'exploitation possède un nombre limité de sockets TCP (canaux de communication dans lesquels sont échangées les données). Pour faire un parallèle simple, lorsque toutes les pompes d'une station service sont occupées, les automobilistes qui arrivent et souhaitent faire le plein, doivent attendre la libération d'une pompe.
Principes des réseaux de distribution de contenu
Les réseaux de distribution de contenu ("Content Delivery Network" ou CDN) ont pour objectif de distribuer un contenu au plus grand nombre selon les conditions suivantes :
- déterminer quel est le serveur du réseau se trouvant au plus près du demandeur
- répondre à la demande en allant chercher l'information sur le serveur d'origine
- stocker l'information récupérée en y associant une durée de conservation
- transférer en réponse l'information au demandeur
- tant que l'information stockée est encore conservable, la distribuer aux prochains demandeurs
En résumé, le CDN s'apparente à un réseau intelligent qui redirige les demandes des internautes vers le serveur qui d'un point de vue réseau se trouve le plus près (temps de latence ou nombre de réseaux traversés faibles). Charge ensuite à ce serveur de prendre contact avec le serveur détenteur de l'information (le serveur web maitre) et de stocker en cache les informations.
Bien évidemment, le principe ne s'applique qu'aux contenus statiques et non dynamiques. Si la demande concerne une recherche d'informations en fonction de critères saisis par l'utilisateur, alors la requête ne peut être mise en cache et sera donc demandée systématiquement au serveur web maitre.
Les réseaux CDN sont caractérisés par le nombre très important de serveurs caches dont ils disposent ainsi que leur emplacement aux croisées des noeuds réseaux des grands opérateurs nationaux et internationaux. A l'image d'une raquette de randonnée qui répartit le poids du randonneur lorsqu'il marche sur la neige, les milliers de serveurs cache du DNS permettent de répartir des demandes nombreuses en plusieurs points réseaux répartis géographiquement.
Illustration de l'utilisation d'un CDN
Comme indiqué plus haut, la première étape consiste à déterminer le serveur du CDN au plus proche de l'internaute :
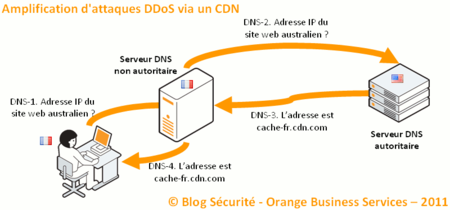 Cliquer sur l'image pour l'agrandir
Cliquer sur l'image pour l'agrandir
Le principe est le suivant :
1. le système de l'internaute interroge son serveur DNS pour connaitre l'adresse IP du serveur web
2. le serveur DNS s'adresse au serveur DNS autoritaire, qui fait partie du réseau CDN
3. le serveur DNS du CDN détermine quelle est le serveur cache le plus proche de l'internaute
4. le serveur DNS de l'internaute lui retourne l'adresse IP déterminée par le réseau CDN
Une fois l'adresse IP en poche, le système de l'internaute va initier une session HTTP avec le serveur cache qu'il pense être le serveur web qu'il souhaite joindre. Il lui demande alors un fichier image (appelé ici "fleur.png") :
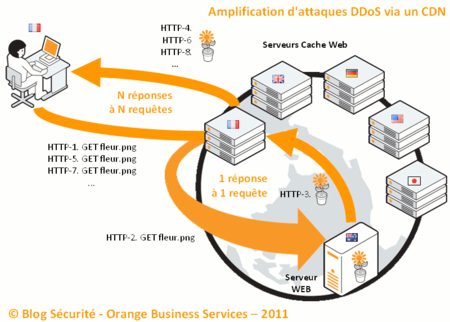
Cliquer sur l'image pour l'agrandir
Le serveur cache choisi par le CDN va alors devoir répondre à la demande de l'internaute en se positionnant lui même comme un internaute vis à vis au serveur web maitre :
1. l'internaute demande le fichier "fleur.png"
2. le serveur cache demande à son tour le fichier "fleur.png" au serveur web
3. le serveur web répond par l'envoi du contenu du fichier image demandé
4. le serveur cache stocke dans son système cache le fichier et le distribue à l'internaute
A présent, si de nouveaux internautes réclament le même fichier du même serveur web au même serveur cache, ce dernier se contentera de leur distribuer le fichier sans solliciter le serveur web maitre :
5. un nouvel internaute demande le fichier "fleur.png"
6. le serveur cache distribue le fichier qu'il a stocké à l'étape 4
7. un nouvel internaute demande le fichier "fleur.png"
8. le serveur cache distribue le fichier qu'il a stocké à l'étape 4
... etc
Attaque DDoS utilisant le CDN
Le système présenté ici vous semble optimisé et capable de répondre à un nombre important de requêtes associées à des contenus statiques. Et bien, détrompez-vous, c'est en substance ce que met en évidence une étude d'une université datant de fin 2009 : "Content Delivery Networks: Protection or Threat ?" (ou "Réseaux de distribution de contenu : protection ou menace ?").
L'étude menée sur trois CDN (Akamai, Coral et Limelight) démontre que ces derniers n'offrent pas le niveau de protection attendu face à des attaques en déni de service, distribuées. L'objectif de telles attaques est par exemple d'inonder un serveur web de requêtes HTTP afin de saturer le système qu'il l'héberge. Au passage, il est fort probable qu'un équipement de protection, de type firewall situé en amont, sature également en laissant passer des flux légitimes mais qui remplissent rapidement sa table de sessions actives.
Le principe de l'attaque se base sur l'incapacité du CDN à traiter les demandes relatives à du contenu dynamique. en ajoutant un paramètre de type QUERY_STRING à la demande, le CDN comprend qu'il s'agit de contenu non statique et s'adresse donc au serveur web maitre :
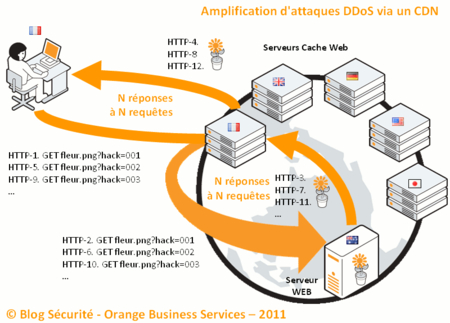
Cliquer sur l'image pour l'agrandir
1. l'attaquant demande le fichier "fleur.png?hack=001"
2. le serveur cache demande à son tour le fichier "fleur.png?hack=001" au serveur web
3. le serveur web répond par l'envoi du contenu du fichier image demandé
4. le serveur cache stocke dans son système cache le fichier et le distribue à l'internaute
Puis l'attaquant reproduit sa demande une nouvelle fois :
5. l'attaquant demande le fichier "fleur.png?hack=002"
6. le serveur cache demande à son tour le fichier "fleur.png?hack=002" au serveur web
7. le serveur web répond par l'envoi du contenu du fichier image demandé
8. le serveur cache stocke dans son système cache le fichier et le distribue à l'internaute
Et ainsi de suite ... opérations 9 à 12. Des requêtes HTTP adressant un contenu statique sont donc assimilées à des requêtes adressant un contenu dynamique. La protection initiale du CDN est donc outrepassée !
Optimisation de l'attaque
En agissant de la sorte, l'attaquant récupère, suite à sa demande, le contenu du fichier demandé. La bande passante utilisée devient donc rapidement chargée entre le serveur cache du CDN et le poste de l'attaquant. En imaginant que l'attaquant agisse via l'utilisation de machines zombies, les propriétaires des machines zombies vont rapidement s'apercevoir de la baisse de leur bande passante et des performances de leur poste, occupé à récupérer les nombreux fichiers demandés.
C'est alors qu'une autre faille des CDN, constatée lors de l'étude, est employée. Partant du constat que les serveurs cache des CDN agissent dans la chaine de traitement comme des postes clients standards (ils initient une demande auprès du serveur maitre, indépendante d'un point de vue TCP de la demande initiale), voici le mécanisme employé :
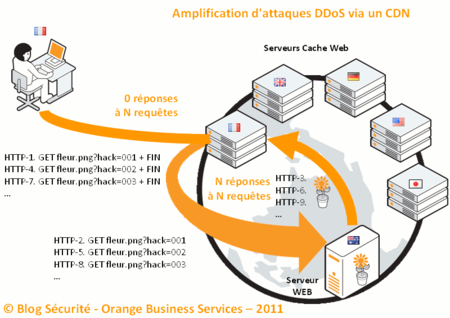
Cliquer sur l'image pour l'agrandir
1. l'attaquant demande le fichier "fleur.png?hack=001" et se déconnecte immédiatement
2. le serveur cache demande à son tour le fichier "fleur.png?hack=001" au serveur web
3. le serveur web répond par l'envoi du contenu du fichier image demandé
Puis l'attaquant reproduit sa demande une nouvelle fois :
4. l'attaquant demande le fichier "fleur.png?hack=002" et se déconnecte immédiatement
5. le serveur cache demande à son tour le fichier "fleur.png?hack=002" au serveur web
6. le serveur web répond par l'envoi du contenu du fichier image demandé
Et ainsi de suite ... opérations 7 à 9. Un effet d'amplification est donc réalisé puisque l'attaquant n'a plus à supporter la bande passante générée par les réponses à ses requêtes HTTP ! L'étude mentionnée plus haut démontre que le concept s'applique aisément sans que les CDN ne repèrent le mécanisme de demandes abandonnées en cours de route ...
Conclusion
Vous remarquerez en reprenant les trois mécanismes de requêtes que nous avons réalisé une optimisation non négligeables :
Scénario "classique"
pour N requêtes client, nous avons N réponses au client
via 1 requête et 1 réponse du serveur maitre
Scénario "attaque"
pour N requêtes client, nous avons N réponses au client
via N requêtes et N réponses du serveur maitre
Scénario "attaque amplifiée"
pour N requêtes client, nous avons 0 réponses au client
via N requêtes et N réponses du serveur maitre
N'oubliez pas non plus qu'en cas d'attaques de ce type, votre solution de protection doit être en mesure de répondre de manière adaptée. En effet, un filtrage trop rapide qui ajouterait les serveurs cache d'un CDN dans une blacklist, vous priverait des toutes les autres requêtes licites en provenance du même CDN.
Il est donc primordial pour les architectes désireux de déployer une solution de CDN, de fortement prendre en compte ces éléments dont l'impact est fort en terme de sécurité. Une configuration particulièrement adaptée aux contenus à distribuer est donc nécessaire (par exemple, ne pas considérer les requêtes de type "/images/*.png" comme du contenu dynamique).
Avertissement : cet article n'a pas pour objectif d'inciter nos lecteurs à mettre en oeuvre des tels mécanismes d'attaques qui n'engageraient que leur responsabilité.
Pour aller plus loin
Définition d'un serveur HTTP: http://fr.wikipedia.org/wiki/Serveur_HTTP
Définition d'un réseau CDN : http://fr.wikipedia.org/wiki/Content_Delivery_Network
Définition d'une attaque DDoS : http://fr.wikipedia.org/wiki/Ddos












SOURCES:
-La carte est une image du docteur Cornish (1933), en pleine tentative de réanimation d 'un cadavre. Il pensait pouvoir ressusciter les mort en réactivant la circulation sanguine grâce à une planche à bascule.
_A lire: le livre Elephants on acid: and other bizzarre experiments d'alex Boese et celui de Laurent Lemire: Les savants fous: d'archimède à nos jours, une histoire délirante des sciences.
_ Si vous ne touchez jamais aux livres, vous pouvez lire article du super site Axolot
_ Je ne résiste pas à la tentation de vous joindre un lien vers un petit article paru dans le site de la revue la Recherche à propos des Bogdanov et de leur livre "le visage de dieu".
Qu'est-ce qu'un « géminoïde » ? Ce terme (ici francisé, au départ geminoid en anglais) à la frontière entre « gémeau » et « droïde » désigne en fait un robot destiné à...
A 00h00 lundi, heure de New York, le groupe Anonymous a fait fuiter une première série de documents – des archives d’emails – censés prouver l’implication active de Bank Of America dans une fraude de grande ampleur. Le site sur lequel ces informations ont été mis à disposition du public est difficilement accessible mais des opérations de mirroring ont rapidement eu lieu afin de parer à toute tentative de censure.
Les conversations que l’on découvre à travers les emails rendus public font apparaître des tentatives de dissimulation d’une vaste fraude à l’assurance crédit, et laissent penser que la catastrophe des subprimes était parfaitement anticipée bien avant qu’elle n’éclate, avec pour seule préoccupation, du coté de la banque et de l’assureur qui s’occupait des assurances liés aux emprunts, de dissimuler ce qui pourrait par la suite les incriminer.
Fail
La fuite viendrait de l’intérieur, comme pour les cables diplomatiques américains, qui aurait fourni à Anonymous une série d’emails echangés entre les membres de la direction de Bank Of America, prouvant, selon lui, l’implication de l’assureur Balboa, racheté depuis par BOA, dans une fraude de grande ampleur sur les assurances liées aux crédits.
L’employé responsable de la fuite, dans ses échange avec Anonymous, souhaite encourager ses collègues à faire de même : “une fois que les autres employés auront réalisé que c’est faisable, vous n’aurez pas seulement une hache pour décapiter une tête, mais 1000 haches pour vous débarrasser de toutes les têtes”.
Le fait de passer par les Anonymous plutôt que de publier ces données sur un site comme Wikileaks est une évolution intéressante de la synergie Wikileaks / Anonymous et les armes choisies par ces derniers pour lutter contre ceux qui combattent la liberté d’expression et justifient la censure de l’internet. Plus mature qu’un DDoS, la stratégie ‘à la Wikileaks’ des Anonymous semble ancrer le concept Wikileaks dans une pratique hacktiviste et ne plus le limiter aux seuls sites de publication qui fleurissent ça et là en ce moment.
Il sera très difficile, pour ne pas dire impossible, de stopper Anonymous sur ce genre d’opérations, tout comme il s’est avéré vain de stopper les pratiques d’une génération habituée à télécharger ses mp3 gratuitement. La boite de Pandore de la surveillance et de la censure est désormais grande ouverte.
Consequences will never be the same
L’analyse de ces documents risque de prendre beaucoup de temps, et il ne faut pas s’attendre à des conséquence concrètes avant un moment. On peut s’attendre, par contre, à une multiplication de ce genre d’opération. Vous pensiez que votre admin réseau était un employé sous payé et inoffensif ?
Think again.
Comme nous l'assurait Bruno Bonnell, la victoire de l'ordinateur Watson au jeu télévisé Jeopardy, équivalent américain de notre Questions pour un champion, représente un exploit important dans l'histoire de l'informatique,...